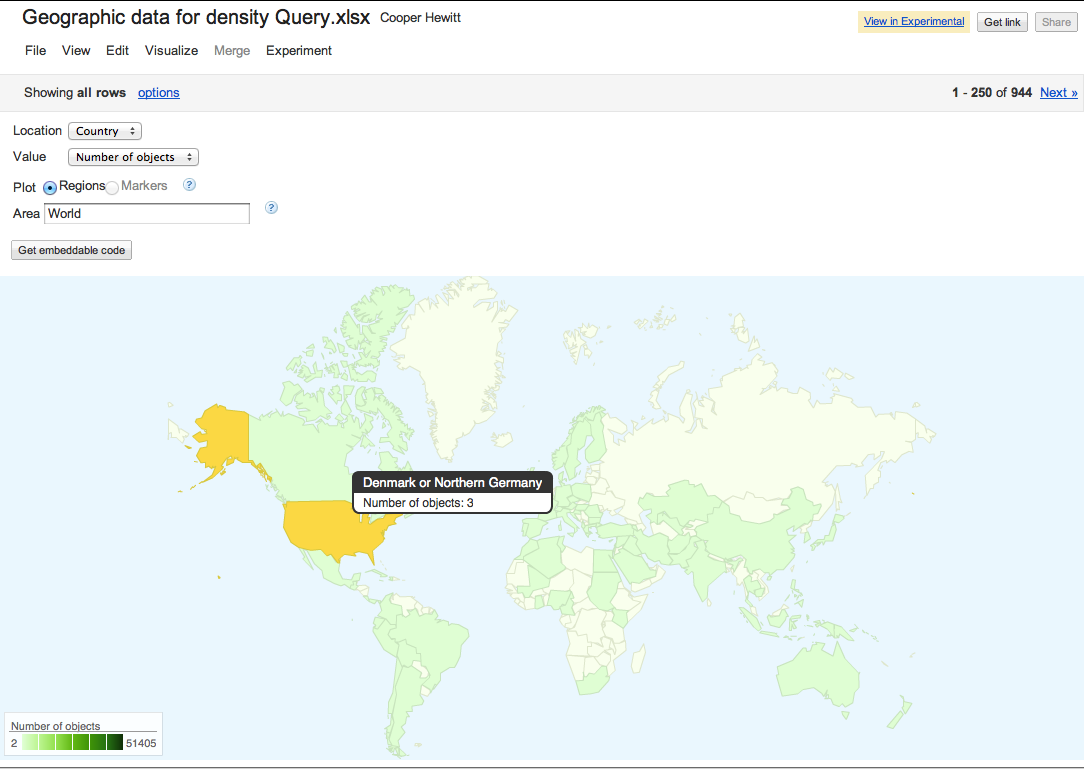
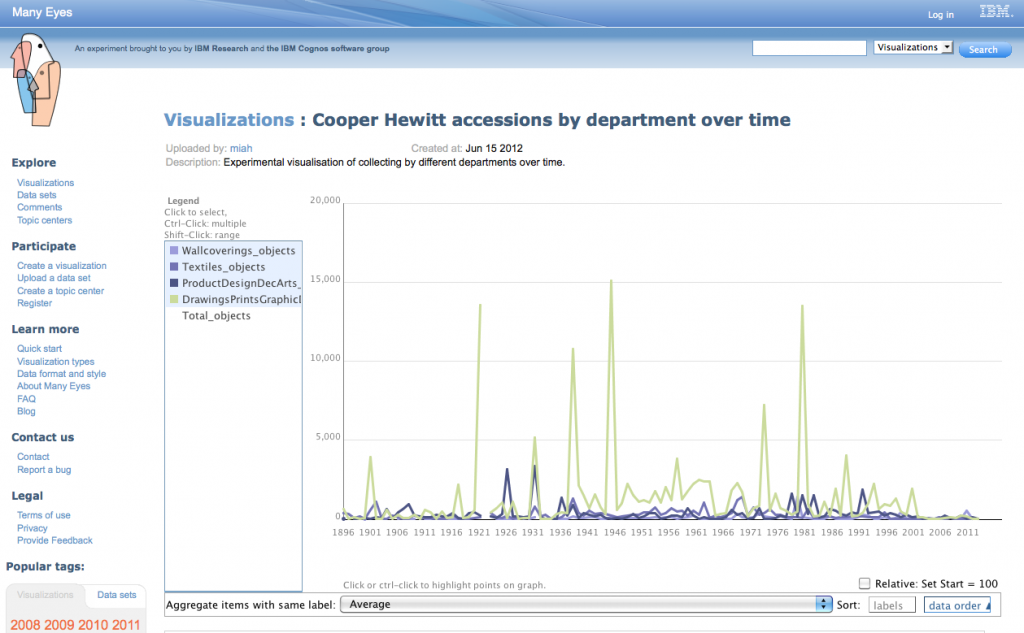
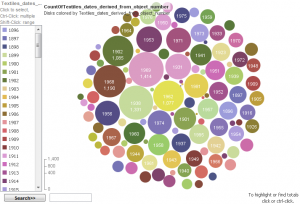
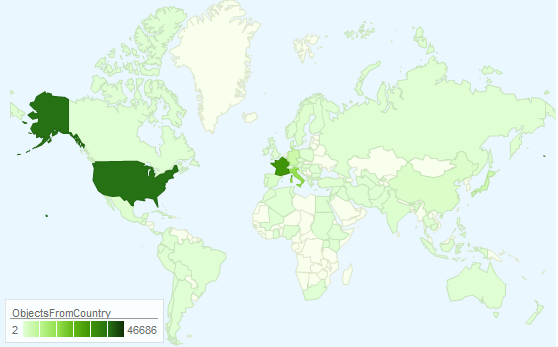
A couple of days ago the Labs hosted a guest to play with our API.
Over to Frankie to explain what he did and the challenges he faced. As it turns out, there’s a lot you can get done in a day.
—
Hi, I’m Frankie Roberto. I used to work at the Science Museum in London, where I produced their web projects. I’ve also worked with museums such as the British Museum whilst at digital agency Rattle. One theme running through all of this time is the importance of data, and the things that it can enable.
So when I learnt that the Cooper-Hewitt Museum had released a ‘public alpha’ of their collections database, the idea of spending a day playing with the data whilst in New York (on holiday!) seemed like it’d be fun. Plus, I get to hang out with Seb & co.
I signed up for a an API account ahead of time. This does feel like a bit of hurdle. Because the API uses oAuth 2.0, as well as creating an account, you then have to create an application, and then authorise yourself against your own application in order to get an access token which ultimately grants you access to the data. This makes more sense for situations where you want to get access to another user’s data (e.g. let’s say that users can bookmark favourite objects and you want to display a visualisation of them). For accessing public data it’s a little overkill. Thankfully the web interface makes it all fairly straightforward.
Ideally, I think it’d be simpler and more developer-friendly not to require API keys at all, and instead to simply allow anyone to retrieve the data with a simple GET request. These can even be tried out in a browser – a common convention is to simply add ‘.json’ on the end of URLs for JSON views. This also lets you use HTTP-level caching, which works at the browser end, the server end and proxies in the middle, keeping things speedy. On the downside, this would make it harder to monitor API usage.
Authentication quibbles aside, once set up I could begin querying the data.
I came to the Cooper-Hewitt knowing very little about the institution other than that it is a design museum. My expectations then were that the collection would be a treasure trove of great design from the past century – things like the Henry vacuum cleaner or the Juicy Salif lemon squeezer by Philippe Starck. In short: ‘design classics‘.
‘Classic’ is a funny word, after abused as a euphemism for old and obsolete, but when applied to design I think it implies quality, innovation, and timelessness – things you might still use today (hence the community around maintaining ‘classic cars’).
My challenge then was to see if, for a given type of thing, I could show the ‘classic’ versions of that thing from the Cooper-Hewitt collection.
To kick off, I looked at the list of ‘types’ in the collection. There are 2,998 of these, and they are for the most part simple & recognisable words or short phrases – things like ‘teapot’ and ‘chair’. The data is a little messy, also including more specific things like ‘side chair’ and ‘teapot and lid’, but, y’know, it’s good enough for now.
I could have retrieved the entire list of types through the API, but as you only get a small bunch at a time, this would have required ‘paging’ through the results with multiple requests. Not too tricky, but rather than coding the logic for this, it was a lot simpler to just import the full list from the CSV dump on GitHub.
The next step was to retrieve a list of objects for each type.
Unfortunately, this didn’t actually seem to be possible using the API (yet). So I went back to GitHub and used the CSV dump of all objects. This contains around a 100,000 objects. Not a huge amount, but with a tip-off from Seb, I realised that I was actually only interested in the objects from the ‘product design’ department – a much smaller list of just 19,848 objects (the rest seem to be mainly drawings and textiles).
With these objects imported, the next step was to match the objects with the types.
This data didn’t seem to be in the CSV file – and it isn’t returned in the API response for object details either (an accidental omission, I think). Stuck, I turned to Seb’s team, and soon learned that what I thought was the object ‘name’ was actually a concatenation of the object’s type and age, separated by a comma. So, I could get an object’s type by simply reversing the process (slight gotcha: remember to ignore case).
At this point I had a database of objects by type, but no images – which for most purposes are pretty crucial.
Ideally, links to the images would’ve been in the CSV dump. Instead, I’d have to query the API for each object and collect the links. Objects can have multiple images, but I only really need the main one, which is designated the ‘primary’ image in the API. Oddly, a good proportion of the objects had no primary image, but did have one or more non-primary images. In these cases, I’d just select the first image.
Script written, I started hitting the API. With 19,848 requests to make, I figured this’d take some time. About a quarter of the way through, I realised that the same data was also available in GitHub, and this could be queried by requesting the ‘raw’ version of the URLs (constructed by splitting the object id into bunches of three digits). So I modified my script to do just that, and set it going, this time starting from the bottom of my list of objects and working up. The GitHub-querying script ran a little faster than the Cooper-Hewitt API (probably not too surprising), and so both scripts ‘met’ somewhere in the middle of the list.
The results of this were that I had images for roughly a quarter of the product design objects, with around 5,000. This seems like quite a lot, but given that lots of these are rather obscure things like ‘matchsafes’, the collection actually isn’t that big, and is rather patchy.
There’s a limit to how many products you can actually collect (and store), of course, and so I’m not suggesting that the museum go on an acquiring spree. But I do wonder whether, to present a good experience online, it might be wise to try and merge in some external product design databases to fill in the holes.
By the time I’d assembled all the data, I didn’t have too much time to consider how to present the ‘classic’ products from among the collection.
Ideally, I think this is something that the museum should expose its expertise in. It can be tempting for museums to pretend that all objects have equal value, but in reality there are always some objects that are considered better, more unique, or in this case ‘more classic’ than others. Museum curators are ideally placed to make these judgement calls (and to explain them). For mass-manufactured design objects, this is arguably more important than collecting them in the first place (it’s unlikely you’d not be able to find an original iPod for an exhibition if you needed one).
Ideas we came up with amongst the team were to try and look up the price of the object on eBay (price isn’t a perfect indicator of design value, but might be a reasonable proxy), or to try and see whether other museums, like the V&A, had also collected the same object.
In the end, I went with a simple crowd-sourcing model. Initially three random objects from each type are picked to be shown as the ‘classic’ ones (3 feels like a good number), with the others shown as smaller thumbnails below. You can then very simply vote objects up or down.

The result of this very simple demo is online at https://designclassics.herokuapp.com – feel free to explore (and vote on the objects).
Thanks to the Cooper-Hewitt for hosting me for the day. I look forward to seeing how the ‘alpha’ collections database develops into the ‘beta’, and then the full launch.
—
If you are an interaction design or digital humanities student, or just a nerd with a bent for playing with museum collections, and you feel like hanging out for a day or two in the Labs to make things then we’d love to have you over.
Drop us a line and we’ll make it happen.