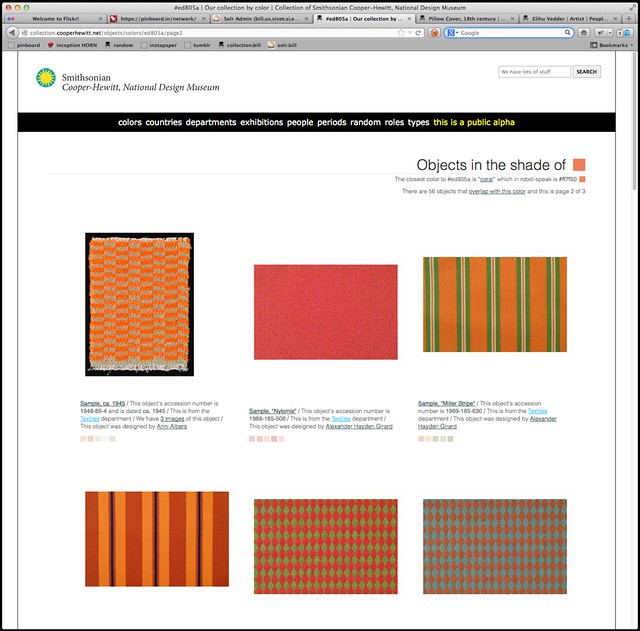
Today we enabled the ability to browse the collections website by color. Yay!
Don’t worry — you can also browse by colour but since the Cooper-Hewitt is part of the Smithsonian I will continue to use US Imperial Fahrenheit spelling for the rest of this blog post.
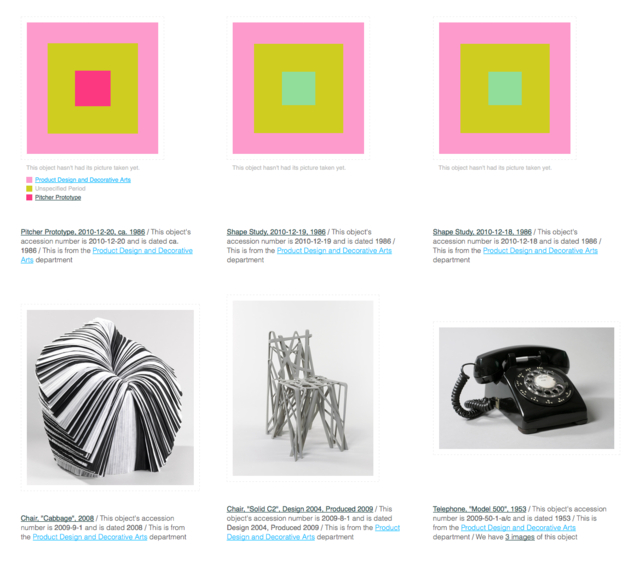
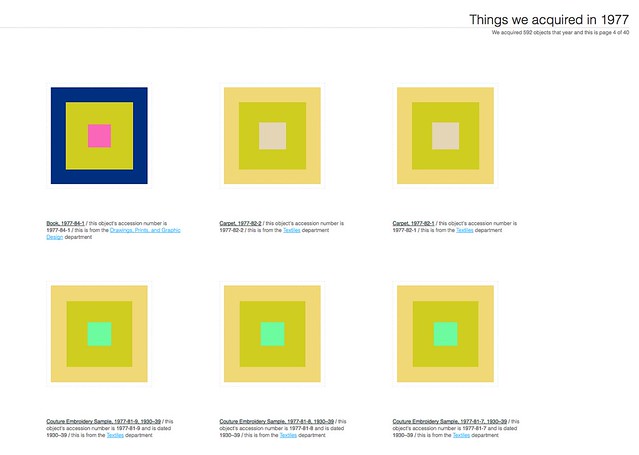
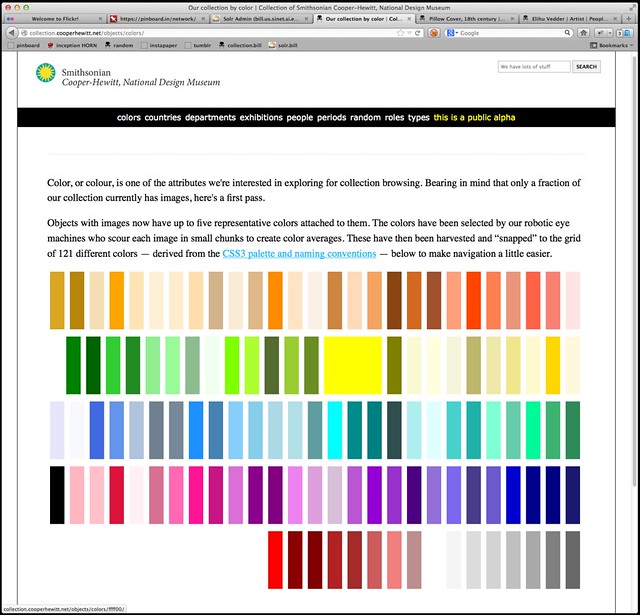
Objects with images now have up to five representative colors attached to them. The colors have been selected by our robotic eye machines who scour each image in small chunks to create color averages. We use a two-pass process to do this:
-
First, we run every image through Giv Parvaneh’s handy color analysis tool RoyGBiv. Giv’s tool calculates both the average color of an image and a palette of up to five predominant colors. This is all based on the work Giv did for version two of the Powerhouse Museum’s Electronic Swatchbook, back in 2009.
-
Then, for each color in the palette list (we aren’t interested in the average) we calculate the nearest color in the CSS3 color spectrum. We “snap” each color to the CSS3 grid, so to speak.
We store all the values but only index the CSS3 colors. When someone searches the collection for a given color we do the same trick and snap their query back down to a managable set of 121 colors rather than trying to search for things across the millions of shades and variations of colors that modern life affords us.
Our databases aren’t set up for doing complicated color math across the entire collection so this is a nice way to reduce the scope of the problem, especially since this is just a “first draft”. It’s been interesting to see how well the CSS3 palette maps to the array of colors in the collection. There are some dubious matches but overall it has served us very well by sorting things in to accurate-enough buckets that ensure a reasonable spread of objects for each query.
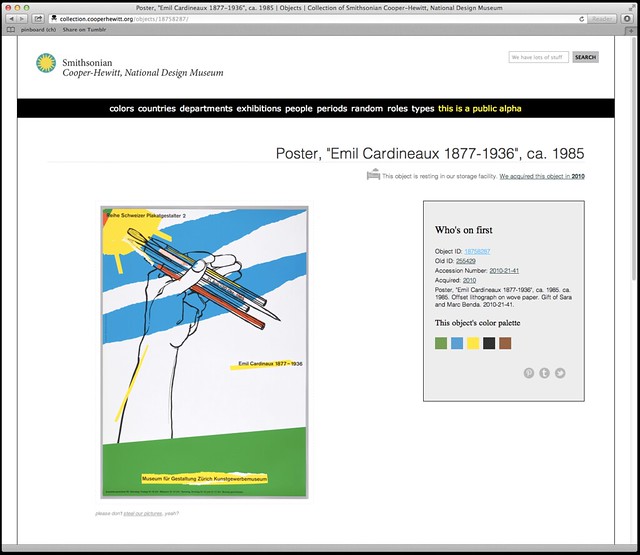
We also display the palette for the object’s primary image on the object page (for those things that have been digitized).
We’re not being very clever about how we sort the objects or how we let you choose to sort the objects (you can’t) which is mostly a function of knowing that the database layer for all of this will change soon and not getting stuck working on fiddly bits we know that we’re going to replace anyway.
There are lots of different palettes out there and as we start to make better sense of the boring technical stuff we plan to expose more of them on the site itself. In the process of doing all this work we’ve also released a couple more pieces of software on Github:
-
color-utils is a mostly a grab bag of tools and tests and different palettes that I wrote for myself as we were building this. The palettes are plain vanilla JSON files and at the moment there are lists for the CSS3 colors, Wikipedia’s list of Crayola crayon colors, the various shades of SOME-COLOR pages on Wikipedia, both as a single list and bucketed by family (red, green, etc.) and the Scandawegian Natural Colour System mostly just because Frankie Roberto told me about it this morning.
-
palette-server is a very small WSGI-compliant HTTP pony (or “httpony“) that wraps Giv’s color analyzer and the snap-to-grid code in a simple web interface. We run this locally on the machine with all the images and the site code simply passes along the path to an image as a
GETparameter. Like this:curl 'https://localhost:8000?path=/Users/asc/Desktop/cat.jpg' | python -m json.tool { "reference-closest": "css3", "average": { "closest": "#808080", "color": "#8e895a", }, "palette": [ { "closest": "#a0522d", "color": "#957d34", } ... and so on ... } }
This allows us to offload all the image processing to third-party libraries and people who are smarter about color wrangling than we are.
Both pieces of code are pretty rough around the edges so we’d welcome your thoughts and contributions. Pretty short on my TO DO list is to merge the code to snap-to-grid using a user-defined palette back in to the HTTP palette server.
As I write this, color palettes are not exposed in either the API or the collections metadata dumps but that will happen in pretty short order. Also, a page to select objects based on a random color but I just thought of that as I was copy-paste-ing the links for those other things that I need to do first…
In the meantime, head on over to the collections website and have a poke around.