
(Rijkscolors are currently disabled as we consider longer-term solutions for cross-institutional browsing and searching. It’ll be back soon!)
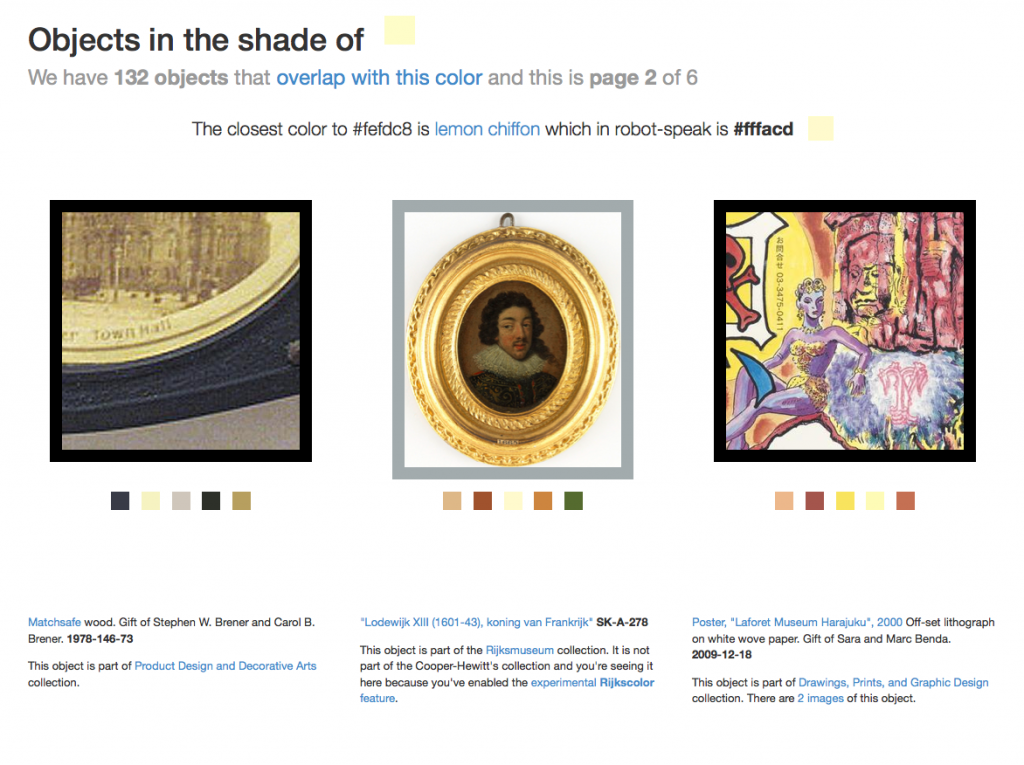
Rijkscolors are an experimental feature that allow you to browse not only images from the Cooper-Hewitt’s collection but also images from the Rijksmuseum by color!
We see this as one way to start to work through the age-old problem of browsing collections across multiple institutions. Not everyone arrives at the Cooper-Hewitt (or the Rijksmuseum) with an expert knowledge of our curatorial and collecting history and the sheer volume of “stuff” available can be overwhelming. Everyone, at some point, has the “Explore” problem: It’s the point where you have so much good stuff to share with people but no good (or many sort-of-bad) avenues for letting people know about it.
Color is an intuitive, comfortable and friendly way to let people warm up to the breadth and depth of our collections. Since adding the ability to search the collection by color it’s quickly become the primary way that people browse our collection (more on that below) and as such feels like an excellent tool for browsing across collections.
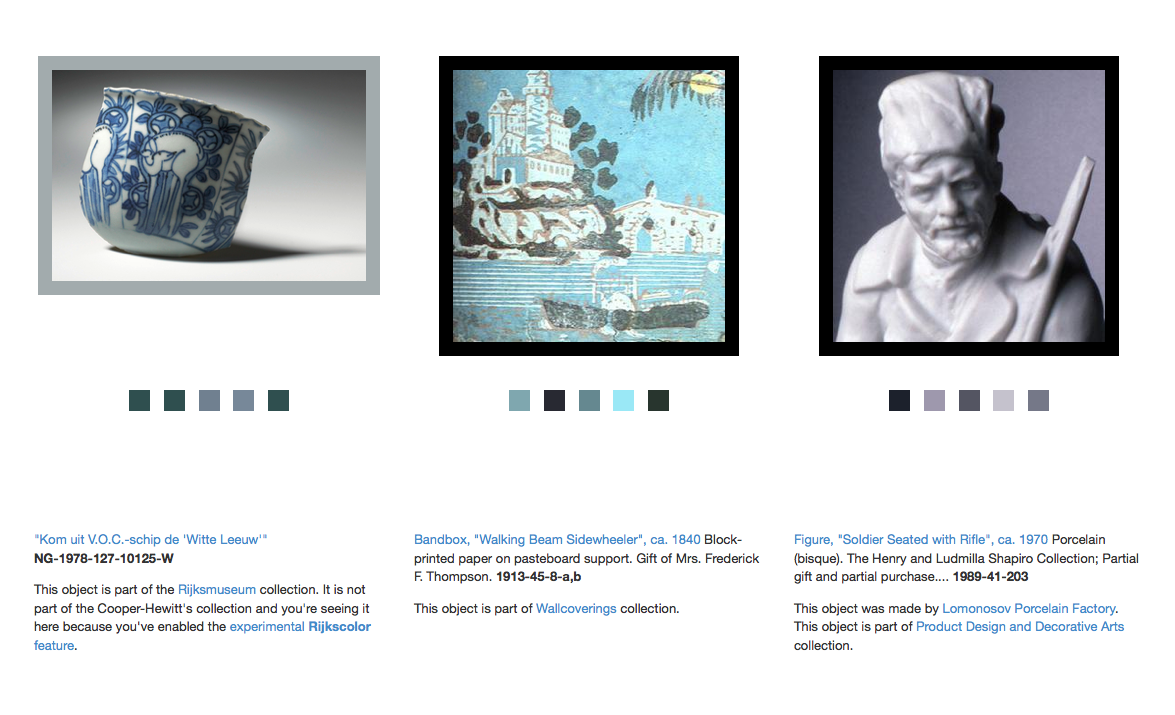
Over time, we hope to add this functionality for many other cultural heritage institutions but chose to start with the Rijksmuseum because we share an historical focus in our early collecting practices and because they were nice (read: AWESOME) enough to make all their collection images available under a liberal Creative Commons license.
We then indexed all those images using the same tools we use to extract colors and measure busy-ness or “entropy” from our own collection and combined the two lists. Images from the Rijksmuseum have a different colored border to indicate that they are not part of our collection. Images from the Rijksmuseum link directly to the page for that object on the Rijksmuseum website itself.

As with the concordances for people we just want to hold hands (for now — Seb tells me this means we might want to move to second base in the future) with other museums and are happy to send visitors their way. After all, that’s what the Internet is for!
Rijkscolors is an experimental feature so you’ll need to enable it on a per-browser basis by visiting the experimental features section of the collection website, here:
https://collection.cooperhewitt.org/experimental/#rijkscolors
But wait, there’s more.
We’ve also made public all the code used to harvest metadata and images from the Rijksmuseum as well as the resultant data dumps mapping colors and entropy scores to Rijksmuseum accession numbers with internal Cooper-Hewitt object IDs. We created a custom mapping because we use Solr to do color search on the website and that requires a numeric ID as the primary key for an object.
Then we imported all the objects from the Rijksmuseum, along with their color values and other metrics, in to our Solr index giving them a magic department ID (aka 51949951 or the Rijksmuseum) and making them private by default. If you’ve enabled Riskscolors when we search for objects by color instead of only asking for things with a given color that are public we ask for things that are public OR part of department number 51949951. Simple!
The code and the data dumps are provided as-is, more of a reference implementation and a toolbox than anything you might use without modifications. We’ve put it all on GitHub and we welcome your suggestions and fixes:
https://github.com/cooperhewitt/rijksmuseum-collection/
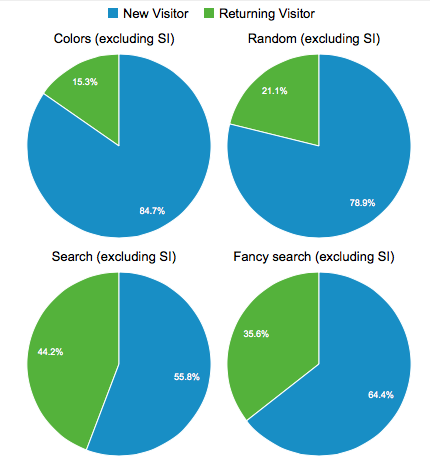
We mentioned search vs browse so let’s take a peek at the last 30 days (Nov 11 to Dec 10, 2013) of visitor behaviour on the collection site.
Or put another way:
- 48.89% of visits used color navigation (anywhere – not just color palette page)
- 4.39% of visits used normal search
- 2.24% of visits used random button
- 1.25% of visits used fancy search
The figures for color navigation are artificially inflated by the press the feature got in Slate, The Verge and elsewhere (the comments are amusing), but even removing that spike, color navigation is at least twice as used as search in the time period. We’ll report back on some new data once December and January are done.
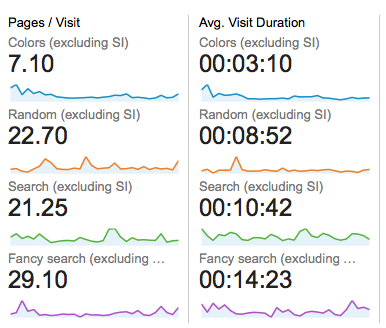
Not unsurprisingly, visitors who use search spend a lot more time on the site and look at many more pages. They are also far more likely to be returning visitors. For newbies, though, color and random navigation methods are far more popular – and still result in healthy browsing depths.
In related news Nate Solas sent us a patch for the palette-server, the tool we use to extract colors from our collection imagery. He said:
“…this improves the color detection by making it a bit more human. It goes two ways: 1) boost all color “areas” by saturation, as if saturated colors take up more room in the image. 2) add a “magic” color if a few conditions are met: not already included, more than 2x the average image saturation, and above the minimum area for inclusion.”
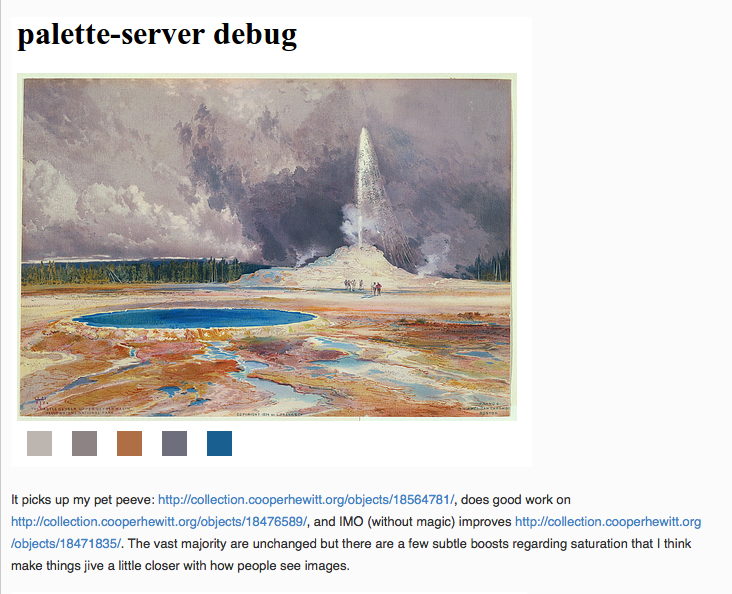
We’ve now merged Nate’s changes in to our code base (technically it’s actually a change to Giv’s RoyGBiv code) and they will be applied the next time we run the color-extraction tools on our collection (and the Rijksmuseum’s collection). Thanks, Nate!
As with all the experimental features they are … well, experimental. They are a little rough around the edges and we may not have found (or even noticed) any outstanding problems or bugs. We hope that you’ll let us know if you find any and otherwise enjoy following along as we figure out where we’re going, even if we’re not always sure how we get there.





{kind=link}