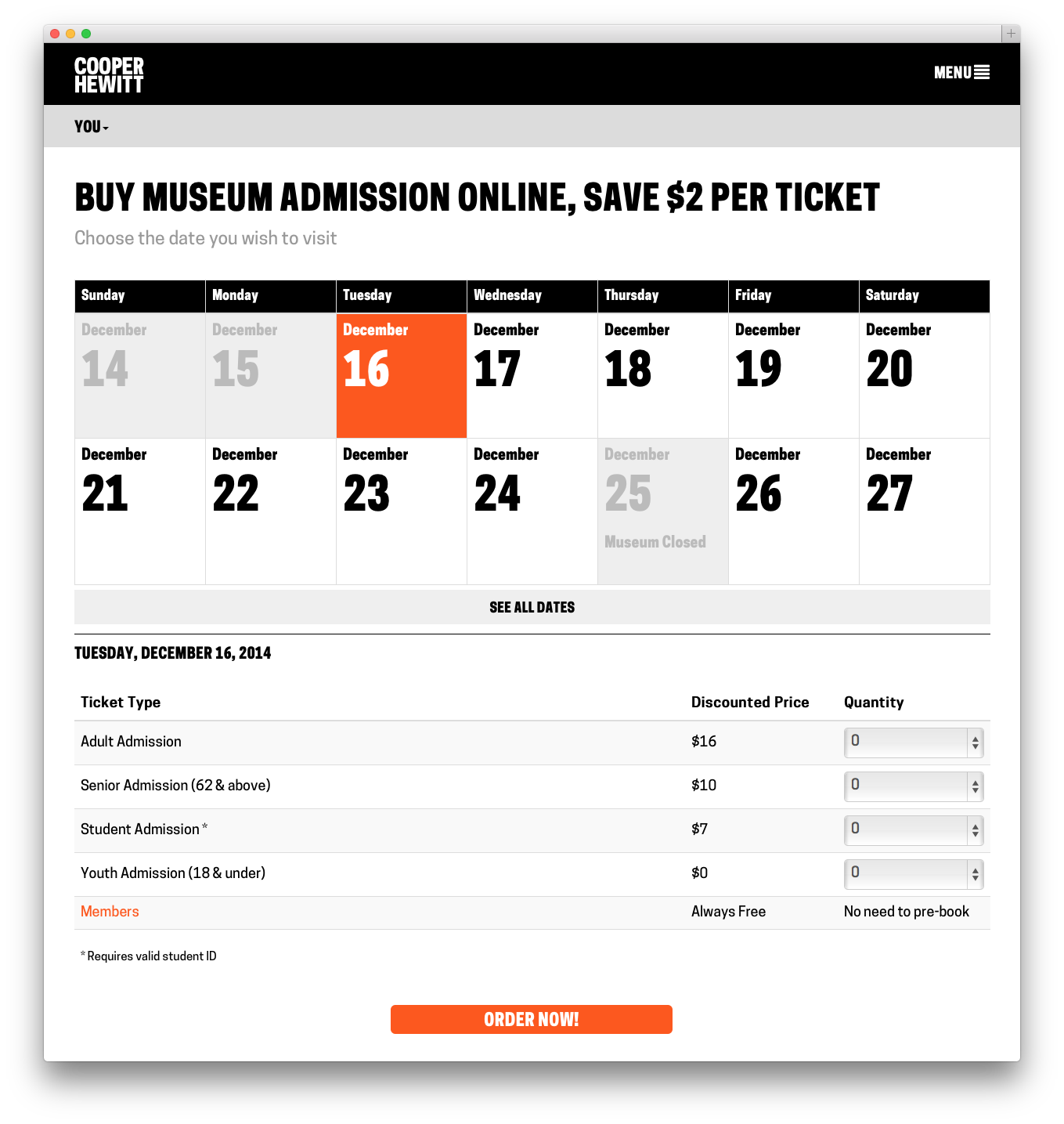
This past week we launched https://tickets.cooperhewitt.org — a new online ticketing system which leverages our Consitutent Relationship Management application, Tessitura, as its “source of truth.”
It’s a simple application, really. It lets you pick the day you want to come visit us, select the kind of tickets you want to buy, and then you fill out your basic info, plug in your credit card digits and off you go. Moments later you receive an email with PDF versions of your tickets attached.
On the user-facing side of things, it is designed to be as simple as possible. You don’t need to log in, there is no “shopping cart”, and above all, you can do all of this from your phone if you want to skip ahead of the lines this Winter on your first visit back since we closed nearly three years ago.
A little background
The idea to pre-book tickets online came at us from a number of directions. Some time last year we decided to invest in Tessitura to handle all of our CRM needs. Tessitura, if you have never heard of it before, is an enterprise class, battleship that grew out of the Met Opera House and has made its way around the performing arts sector. It’s a great tool if you are looking to centralize everything there is to know about a Constituent. As a museum, it is also appealing in that it does many of the things that non-profit type cultural institutions need to do out of the box.
So, Tessitura. It is now a thing at our museum. Everyone on our staff started ramping up on the software and getting settled into the idea of using Tessitura for one thing or another. Our department began to get requests.
Obviously our membership department would like to use Tessitura to sell and manage memberships. Development would like to use it to manage and collect donations and gifts. Education would like to centralize all public programs, book tours, manage special events, and all of the other crazy things they do. And did I mention we have a museum that sells tickets?
This is how it always starts. The avalanche of ideas, whiteboard sessions, product demos and gentle emails that say things like “When will Tessitura be ready?” begin to pour in. You have to soak it all in and then wring it all out.
The Simplest, Dumbest Thing
Aaron says that quite often. “Just do the simplest, dumbest thing…” and he’s right. Often times you have to boil things down a bit to get to the real core issues at hand. It was clear from the start that this would be an essential part of the “design process” on this project.
So, I started out by asking myself this question: “What is the most basic thing we want to do with Tessitura?”
I wound up with two clear answers.
- We wanted to be able to sell tickets online. Just basic, general admission tickets. Nothing fancy yet.
- We eventually want to use Tessitura as our identity provider, and as a way to pair your ticket with the Pen. More on that towards the end…
Tackling Tickets
So to get started, I thought about the challenge of selling a ticket online. I looked at other sites I liked such as StubHub, EventBrite, and other venue websites that I knew used Tessitura like BAM, Jazz at Lincoln Center, and the 92Y. I did some research, I bought some tickets, and I asked all my friends who used these sites what they liked and disliked. Eventually I started to find my way gravitating towards the Eventbrite way of doing things. We have been using Eventbrite for a couple of years here at Cooper Hewitt, for the most part as a way to sell tickets to education programs and events.
To tell you the truth, Eventbrite has been a dream come true for us and our sales for these events, both paid and free, have been very good. So, what is Eventbrite doing right? Simply put they’ve made the process of purchasing a ticket to an event online stupidly simple.
I wanted to know more. So, I spent some time and slowly walked myself through the process of booking all kinds of things on Eventbrite. I tried to step through each page in the process, I tried to notice what kind of user feedback I got, and what sort of emails and notifications I got. I tried the same on mobile devices and through their iPhone app. Here are a few takeaways.
- You don’t need to register in order to purchase a ticket on Eventbrite.
- If you don’t register when making an initial purchase, you can register later and see your purchase history.
- As soon as you book your tickets, you get them in an email.
- The Thank You page is just as useful when you are logged out as when you are logged in.
- Most importantly, you can only buy one thing at a time. In other words, there is no idea of a Shopping Cart.
That last one was pretty huge. Most eCommerce sites are built around the idea that users put items in a cart and then “Checkout.” Eventbrite doesn’t do it this way. Instead, you simply pick the thing you are wanting to attend, select the kinds of tickets you want ( student, senior, etc ) and then put in your credit card info. Once you hit submit, you’ve paid for your tickets and your transaction is complete.
I felt this flow was incredibly powerful and probably one of the reasons Eventbrite was working so well for our education programs. There are simply less chances to change your mind, less confusion over what you are buying, and the end-to-end process of picking something out and paying for it is just so much smaller than the more traditional shopping cart experience.
I began to think of it kind of like the difference between getting your weekly groceries and just picking up a six pack. The behaviors are totally different because you are trying to accomplish two totally different tasks. One is very routine, requires a little creativity and some patience, and a willingness to wander around and “pick.” The other is a strategic strike, designed to get in and get out so you can get home and relax with a nice cold one.
The Eventbrite concept seemed like what we wanted. I had my simplest dumbest thing, and something to model it on.
Technical Challenges
With every new project comes some kind of technical challenge(s). Tessitura is a “new to us” application and our staff at Cooper Hewitt were clearly at the bottom left of a steep learning curve when we started the project. We also had many challenges we knew we were going to have to face because we are a “Governmental Institution.” So things like PCI compliance, complex network configurations, and security scans were all things I was going to need to learn about.
Tessitura comes with two APIs. One is a somewhat older ( as in the first thing they built ) SOAP API, and the other is a newer ( as in still under development ) REST API. Both allow data to get in and out of Tessitura in a variety of forms.
In addition to the standard SOAP and REST APIs, Tessitura has the facility to expose just about anything you can build into an MS SQL Stored Procedure through its API. This is an incredibly powerful feature, which can also be quite dangerous if you think about it.
When I attended the Tessitura Learning Conference & Convention this past summer, it became clear to me that many institutions that use Tessitura are building some kind of API wrapper, or some type of middleware that helps them make sense of it all. We chose to do the same. To accomplish this, I chose to model the API wrapper off our own Collections API, which is a REST-ish API based on Flamework, and uses oAuth2 for authentication. Having this API wrapper allows us to all speak the same language and use the same interface. It is also very, very similar to the Collections API, so among our own staff, it is pretty easy to navigate. The API wrapper, wraps methods from both the Tessitura SOAP and the REST APIs and presents a unified interface to both of them. It doesn’t implement every single API method, and it exposes “new” methods that we have custom built via those Stored Procedures I mentioned.
The Tickets website is a separate project that talks directly to the API. It is also a Flamework project, written primarily in PHP. It uses a MySQL database to store a small amount of local data, but for the most part it is making calls to the API wrapper, which in turn is making calls to either the SOAP or REST Tessitura APIs. Tessitura is the source of truth for most of the things the Ticketing website does.
The Front End
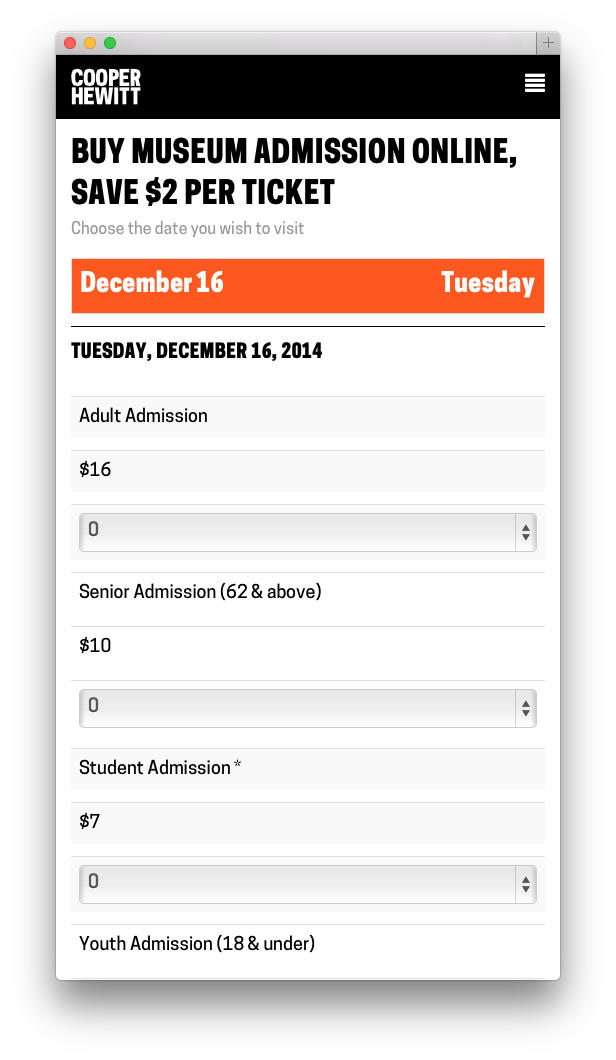
The Tickets site from the user’s perspective is designed to be extremely simple. I worked with Sam ( our in house front end guru ) to build a responsive, and simple web application that does basically one thing, but the devil is always in the details.
At first glance, all the site does is allow you to select the day you want to come visit us, pick out what kinds of tickets you want, and then fill out your billing info and receive your tickets. It’s basically a calendar and a form and not much more. But like I said, the devil is in the details.
First, Sam built a beautiful calendar like one I’d never seen before. We talked at length about how dumb most website calendars were, and we tried to push things in a new direction. Our calendar starts out by showing you what you most likely are looking for–Today. It displays the next bunch of days up to two weeks worth by default, and if you are looking for a special date, it lets you drop down and navigate around until you find it. On mobile its slightly different in that it doesn’t show you any past dates ( why would you want to book the past? ) and it limits things a little so you’re not as overwhelmed by the interface. We call this “designing for context” and we thought that users might be using their mobile phones to buy a ticket online and jump up to the front of the queue.
Once you’ve selected the date you want, the app loads up the available tickets right below the calendar. You can easily change your mind and pick a different date. From here you just select the type and quantity of each ticket you want. Sam’s code does a bunch of front-end validations to make sure everything you are trying to do makes sense ( you can only purchase a youth ticket with another paid ticket for example ). Between the two of us, we try to do as much validation to what you are selecting as possible, both in Javascript on the front-end and in PHP on the back.
Once you hit Order Now, an order form is generated and displayed. I think its important to note here that nothing has really happened yet in Tessitura-land. We asked Tessitura for some details about the tickets you are interested in, but we haven’t “added them to your cart” or anything like that as of yet.
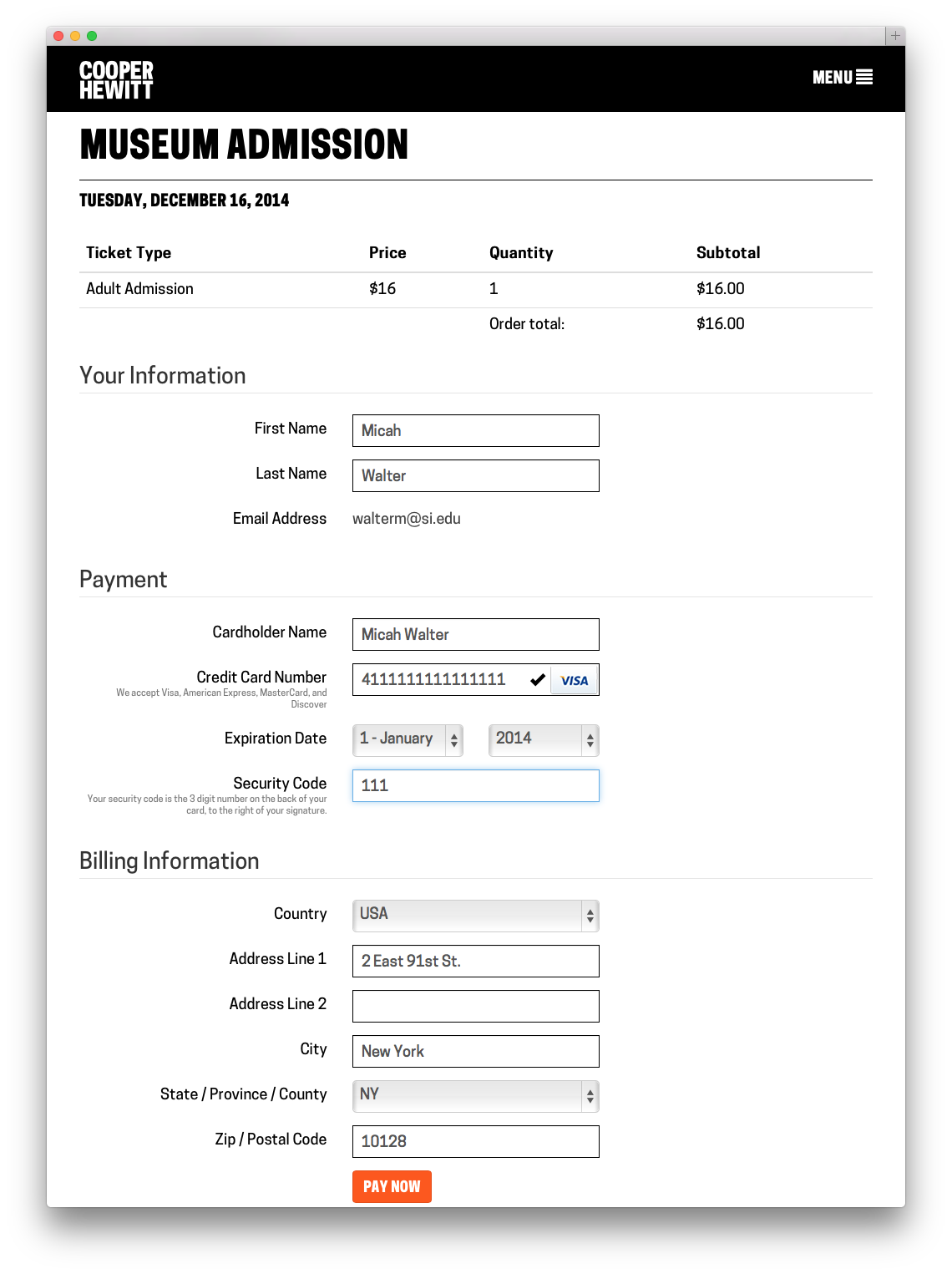
You can then fill out your vitals. We ask you to give us your name, email, credit card details and billing address. We store all of this, with the exception of your credit card, in Tessitura. We make you an account, and at this point we send you an activation email which allows you to set up your password at your leisure. If all goes well with your credit card, we build your tickets ( I chose to do all this with FPDF rather than try and use Tessitura’s built in Print at Home server thing ) send them in an email, and then take you to a Thank You Page. You never had to register, or log in, and you technically never do. Your PDF tickets arrive in your inbox and that is technically all you need.

As a little bonus, we just stick the barcode and some basic metadata about each ticket you bought on the Thank You Page so you can just present your phone at the door. This part is still a little rough and I chose to leave it that way for the time being so we can do some user research in the galleries. It’s a nice feature, but only time will tell if people actually use it or if it needs some finesse.

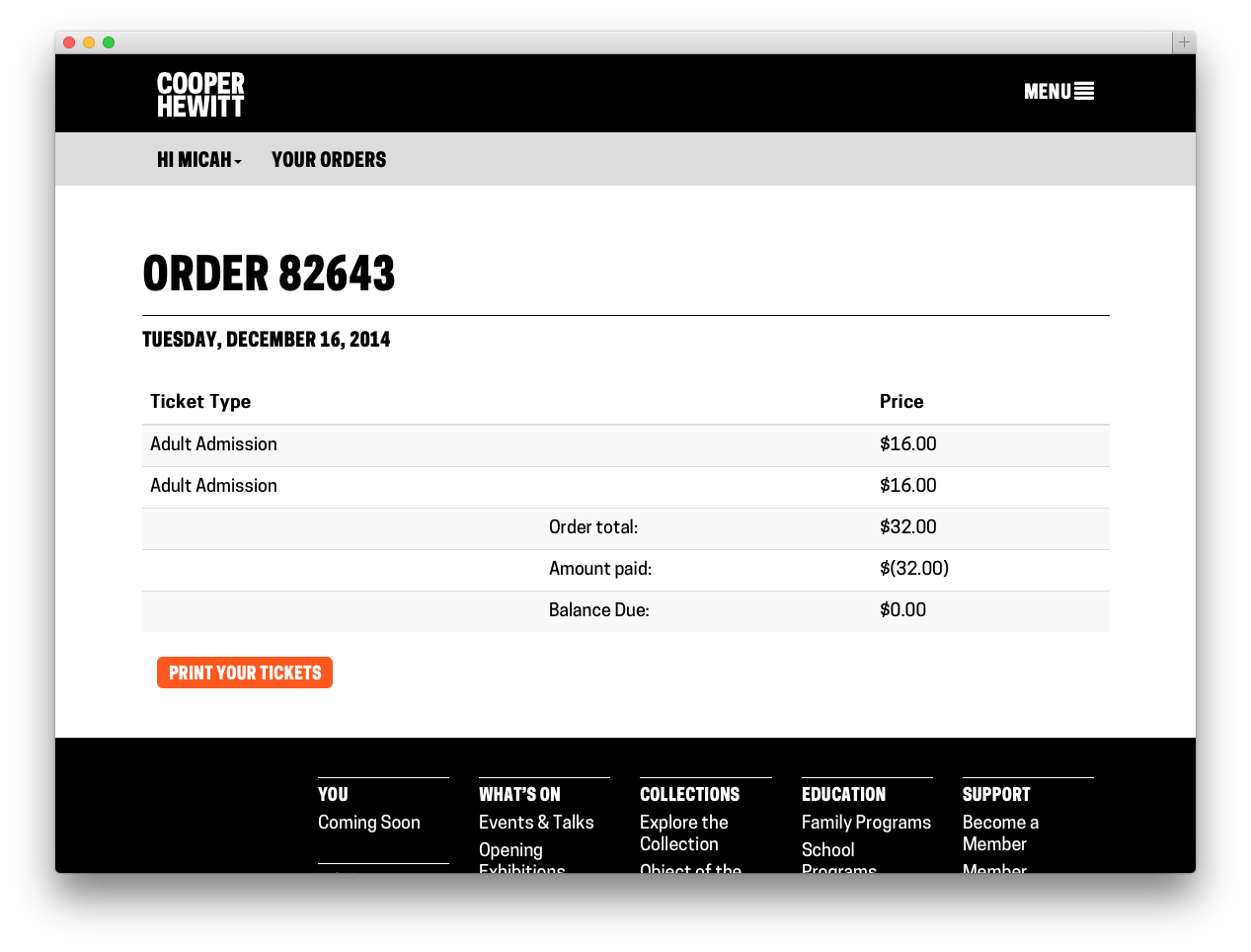
Now that you are in the system, you can buy more tickets using the same email address and they will be connected to your same account, even if you still have never logged in. If you do choose to activate your account and login, you can look at your order history, and reprint your tickets if you’ve lost your email copy.
Tessitura & The Pen
A while back in this blog post, I mentioned that we also wanted to use Tessitura as our identity provider and as a way to pair the ticket you’ve purchased with the pen we’ve handed you. This work is nearly done, but not yet in production. It will go live when our pen is available sometime in early 2015. But, the short story is, when you buy a ticket, either online or in person, we generate a special coded version of your ticket. This code gets paired up with the internal ID of the pen we gave you and that pairing gets stored in a database. What this all amounts to is that when you get home, and you want to see all the cool things you’ve done with your pen, you simply enter the code ( or go to a custom short URL ) on our website. We look up your pairing and are able to connect your Identity ( Tessitura ) with your Visit ( on the Collections site ). But that is all the topic of a future series of blog posts.
Next
Now that the Tickets site is up and running, and we are watching the sales roll in, it’s easy to start thinking of more features and new ways to expand what the site can do. I’ve already started building simple admin tools and have been thinking about building a basic check-in app for off-site events. It’s too early to talk about all of the things we aim to do and how we plan to expand our online sales, but I’m hopeful that we will stay focused and narrow in our approach, offering our users the most elegant visitor experience possible. Or at the very least, the simplest, dumbest thing.








{kind=link}