
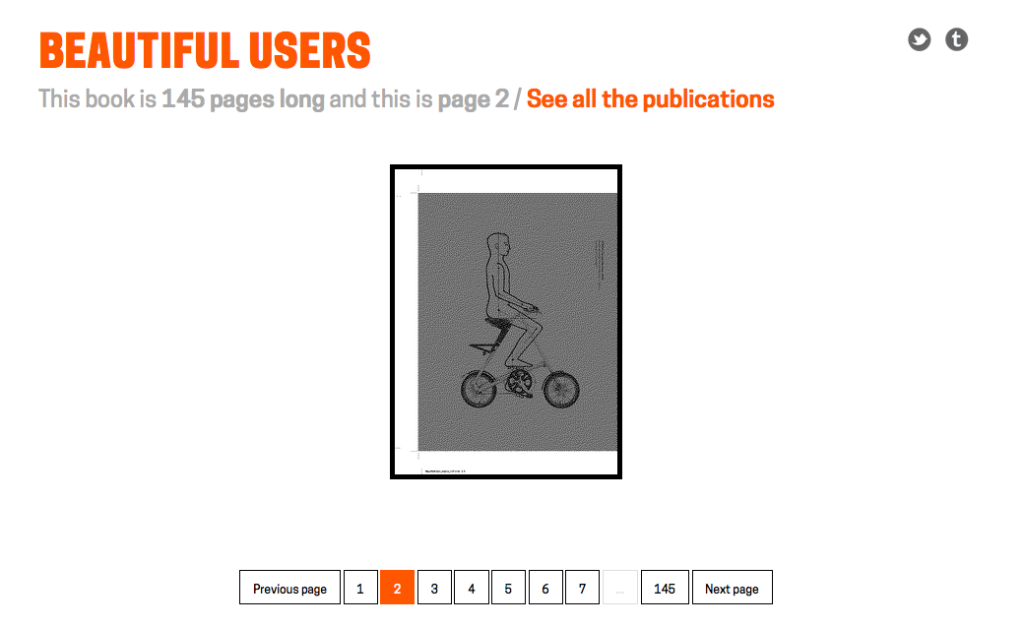
Note: This book is actually 144 pages long and the count is a by-product of the way we’ve stitched things together. By the time you read this that problem may be fixed. So it goes, right?
We’ve added a new section to the Collections website: publications. You know, books.
This is the simplest dumbest thing we could think of to create a bridge between analog publications and the web. It’s only a handful of recent publications at the moment and whether or not older publications will be supported remains an open question, for now.
To be clear – there are already historical publications available for viewing on the main Cooper Hewitt website. As I was writing this blog post Micah reminded me that we’ve even uploaded them in to the Internet Archive so you can use their handy book reader to view the books online. All of which means that we’ll likely be importing those publications to the collections website soon enough.
All of this (newer) work is predicated on the fact that we have the luxury, with these specific publications, of operating outside the “work” versus “edition” dilemma that many other kinds of books have to negotiate. All we’ve done is created stable permanent URLs for each book and each page in that book. That’s it.
The goal is not to reproduce the book online, for all the usual reasons, but to give meaningful atomic units of a book – pages – a presence on the Interwebs and a scaffolding for future stuff (object lists, additional photographs, notes and other ancillary materials and so on) as time and circumstance permit.
Related, Emily Fildes’ and Allison Foster’s Museums and the Web (2015) paper
What the Fonds?! The ups and downs of digitising Tate’s Archive is a good discussion around the issues, both technical and user-facing, that are raised as various sources of disparate data (artworks, library and archive data, curatorial files) all start to share the same conceptual space on the web.

We’re not there yet and it may take us a while to get there so in the meantime every page URL has a small half-toned reproduction of the book page in question. That’s meant to give people a visual cue and confidence in the URL itself — specifically they look the same — such that you might bookmark it, share it with a friend, or whatever awesome use you dream up without having to wonder whether the ground will shift out from underneath it.
Finally, all the links indicating how many pages a particular book has are “magic” – click on them and you’ll be redirected to a random page inside that book.
Enjoy!



![Single visit 'lifecycle' of The Pen. Illustration by Katie Shelly, 2015. [click to enlarge]](https://www.cooperhewitt.org/wp-content/uploads/sites/2/2015/04/PenCycle_v3.png)