
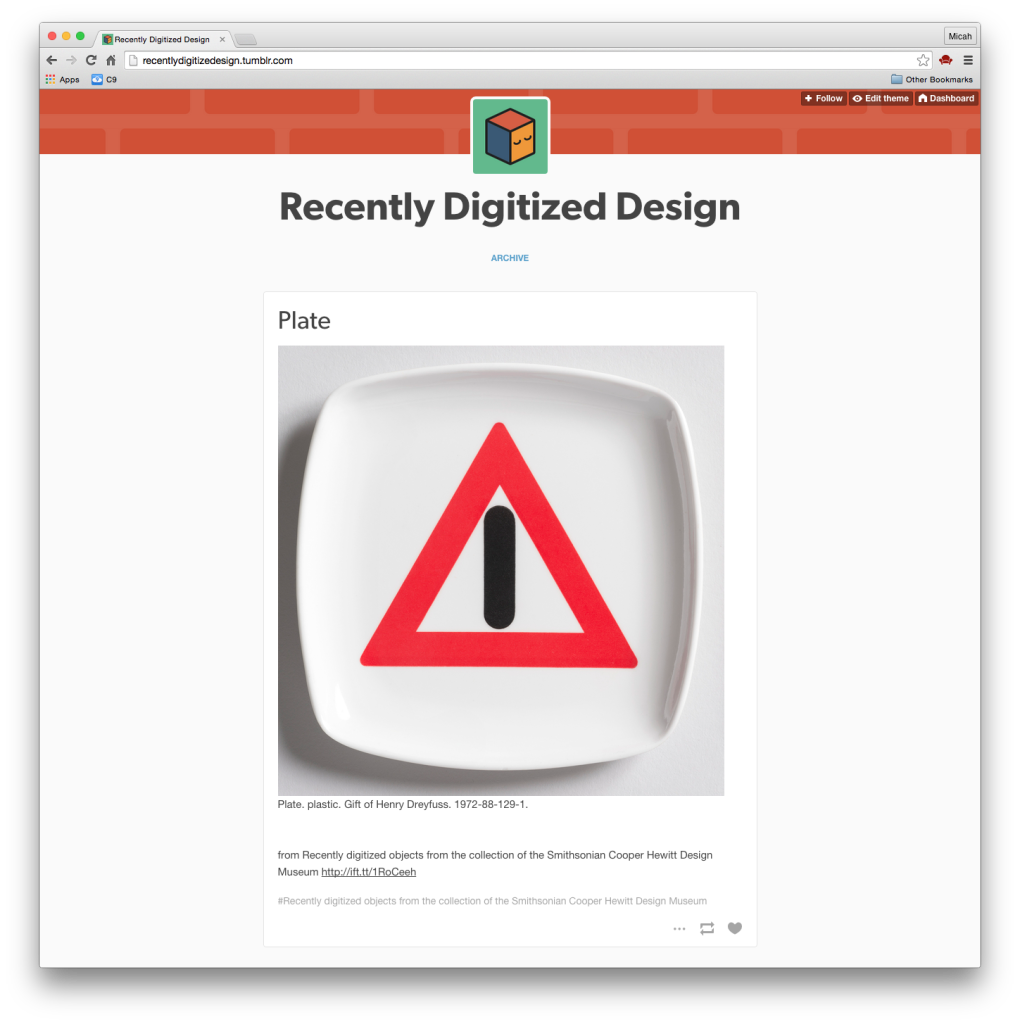
I just made a new Tumblr. It’s called “Recently Digitized Design.” It took me all of five minutes. I hope this blog post will take me all of ten.
But it’s actually kinda cool, and here’s why. Cooper Hewitt is in the midst of mass digitization project where we will have digitized our entire collection of over 215K objects by mid to late next year. Wow! 215K objects. That’s impressive, especially when you consider that probably 5000 of those are buttons!
What’s more is that we now have a pretty decent “pipeline” up and running. This means that as objects are being digitized and added to our collections management system, they are automatically winding up on our collections website after winding their way through a pretty hefty series of processing tasks.
Over on the West Coast, Aaron, felt the need to make a little RSS feed for these “recently digitized” so we could all easily watch the new things come in. RSS, which stands for “Rich Site Summary”, has been around forever, and many have said that it is now a dead technology.
Lately I’ve been really interested in the idea of Microservices. I guess I never really thought of it this way, but an RSS or ATOM feed is kind of a microservice. Here’s a highlight from “Building Microservices by Sam Newman” that explains this idea in more detail.
Another approach is to try to use HTTP as a way of propagating events. ATOM is a REST-compliant specification that defines semantics ( among other things ) for publishing feeds of resources. Many client libraries exist that allow us to create and consume these feeds. So our customer service could just publish an event to such a feed when our customer service changes. Our consumers just poll the feed, looking for changes.
Taking this a bit further, I’ve been reading this blog post, which explains how one might turn around and publish RSS feeds through an existing API. It’s an interesting concept, and I can see us making use of it for something just like Recently Digitized Design. It sort of brings us back to the question of how we publish our content on the web in general.
In the case of Recently Digitized Design the RSS feed is our little microservice that any client can poll. We then use IFTTT as the client, and Tumblr as the output where we are publishing the new data every day.
RSS certainly lives up to its nickname ( Really Simple Syndication ), offering a really simple way to serve up new data, and that to me makes it a useful thing for making quick and dirty prototypes like this one. It’s not a streaming API or a fancy push notification service, but it gets the job done, and if you log in to your Tumblr Dashboard, please feel free to follow it. You’ll be presented with 10-20 newly photographed objects from our collection each day.
UPDATE:
Today in the office . . . “Twitterbot or it doesn’t exist” (especially for @micahwalter)
— Seb Chan (@sebchan) July 10, 2015
So this happened: https://twitter.com/recentlydigital





{kind=link}