
We launched the alpha version of the new collections website at the end of September. Then I spent a good chunk of the next two months, on the road, talking about it. Or talking around it, sometimes.
There’s the nerdy nerd version with walks through some of the technical architecture and statements of bias for those choices. This was one half of a talk that I did with Micah at the Museum and Computers Network conference (MCN) in November.
It’s nerdy but just as importantly it discusses the reasons why we chose to do things the way we have. Namely that: The speed with which the code running an application can be re-arranged in order to adapt to circumstances. This is not the only way of doing things. Other museums may have legitimate reasons for a slower more deliberate pace but given that we are in the middle of a ground-up renovation and re-imagining of the museum and given the nature of the squishy world of design we don’t.
The other talks bracket the one we did at MCN. There is a long talk and a very very long talk. They are the “think-y” talks. Both were funhouse-mirror keynotes delivered first at Access 2012, a libraries and technologies conference, in Montreal and then a month later at the New Zealand National Digital Forum (NDF) in Wellington.
Both talks are, ultimately, very much about the work we’re doing at the Cooper-Hewitt and the core of each keynote covers the same shifting ground that define our daily grind. Neither talk is a timeline of events or a 12-step songline for re-inventing your museum or the mother of all product demos. Those have their place but I don’t think that a keynote is one of them.
I chose instead to ask the question of why we bother collecting any of the stuff we keep hidden away in our storage facilities in the first place and to work through the claim that the distinction between museums and archives, and by extension libraries, is collapsing in most people’s minds. Assuming it every existed in the first place.
In between (or rather before) all this talking was even more talking. In October I attended To Be Designed (TBD), a three-day design fiction workshop held in Detroit. The goal of TBD was to produce, from scratch, a near-future product catalog and in the process the experience worked its way in to every other talk I did in 2012.
I also spoke with James Bridle and Joanne McNeil as part of Rhizome’s Stories from the New Aesthetic, at the New Museum. My talk doesn’t actually hold hands with any of the other “museum” talks but does sort of wink at them from across a crowded subway car. It was also the first time this slide, which has shown up in every subsequent talk, appeared.

Because this is what 2012 looks like for museums.
It is most definitely not about Twitter but about the fact that some random person out there on the Internet is building a record of understanding about Roombas that may well rival anything we will ever do ourselves.
Beyond that, we are being forced to accept the fact that our collections are becoming “alive”. Or at least they are assuming the plausible illusion of being alive.
We are having to deal with the fact that someone else might be breathing life in to our collections for us or, frankly, despite us. We are having to deal with the fact that it might not even be a person doing it.
These earlier talks were the soundtrack music. They were soundtrack music in a busy room with lots of people talking. The reason I mention them here is because the place where I think they overlap with the three “museum” talks is at the intersection of motive and how we understand its consequences and how we measure it in a world where the means of production are no longer much of a proxy for anything.
Motive and desire. Desire and means.
The good news is that this is okay. This is better than okay. This presents an opportunity that we’ve never had before and we have proven, by the work that precedes us, that we are not complete morons so I believe we can make something of this.
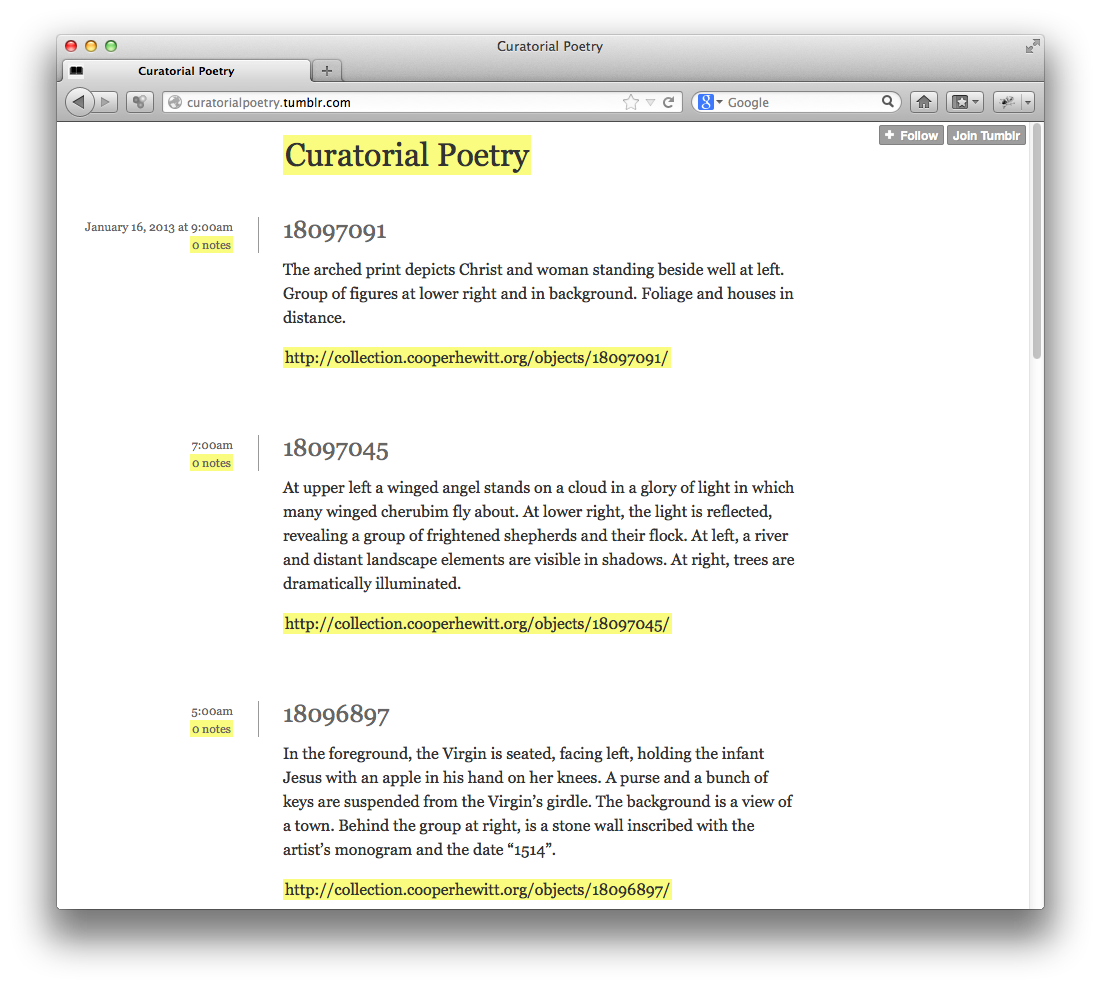
The bad news is that we are competing with Tumblr. Not Tumblr the company but the ability to, more easily than ever before, collect and catalog and investigate a subject and to share — to publish and to distribute — that knowledge among a community of peers.
Which sounds an awful lot like classical scholarship to my ears. Even if the subject happens to be exercise treadmills. Or tyre swans.
Call me naive but I thought that we had decided that what was important was measuring people on the rigour and merit of their study and not so much on the subject themselves. We’ve been bitten by those blinders so many times already that maybe we could just get past them this time?
Because people are going to do this. They are going to build catalogs and registries and pointers to the things in their life and they are going to put them online so that they have… a center of mass around with the rest of their lives can orbit.
But most important of all is that people are going to do this because they have the means at their disposal. We no longer operate in a world where we have any kind of special access to the means of production and no one is ever going to go back to that world, at least not willingly.
Ask yourselves this: Why didn’t David Walsh give his collection to one of our museums? I am less concerned with the answer than with the question, in this case. MONA is the far end of the spectrum when we talk about what’s possible. David Walsh has, I’m told, more money than the sky but squint your eyes a bit and you see not money but means and desire.
Now look back at the internet.
So, what’s happened between then and now? Aside from just getting back to thinking about and sweating the details as we look towards 2014 the Labs team had a meeting, with a visiting museum nerd, a couple weeks ago.
We were sitting in one of the bigger conference rooms so there was a projector resting in the middle of the table surrounded by a small inanimate support staff of VGA dongles. At one point Seb picked up one of the dongles and asked: How do we (the Cooper-Hewitt) show something like this?
It seems like a throwaway question and in some ways it is. The simultaneous peril and opportunity of a design museum is that our mandate is to consider the entire universe of objects like this. Think of everything you’ve ever known about formal design and aesthetics multiplied by automated manufacturing and distributed openly available databases of designs (and gotchas) and then multiplied again by the steady, plodding march of technology.
And there’s the rub: The VGA dongle is made even more fascinating in that light. All VGA dongles are the same at one end. The end with the VGA adapter. The end with the weight of a black hole that the computer industry despite all their best efforts, and advances, can’t seem to escape.
In fairness we might just barely be starting to see a world beyond VGA in that fewer and fewer devices are using it as their default input standard but I suspect it will still be another five (probably ten) years before it will be unnecessary to ask whether there’s a VGA-to-whatever adapter.
And that’s the other end of the adapter. That whole other world of trying to improve or re-imagine video display. That whole other world of computers and other equally real and conceptual “devices”, at the end of those adapters, that we can use a way to understand the shadows of our history.

That would be an awesome show, wouldn’t it?
And if someone wanted to they could just set up a Tumblr (or whatever) account and grab all the press shots for each dongle from Amazon. There’s probably even a decent opportunity for corporate sponsorship in the form of affiliate/referral links or simply Google Ad Words ads.
A comprehensive cataloging of images of VGA dongles does not an archive, or an expert or a scholar, make but it is a pretty important piece of the puzzle. And what happens when that random person with a Tumblr account writes — and posts — the most comprehensive history of VGA dongles the world has ever seen? Everyone remembers the epic 9, 000 word Quora post on airplane cockpits, right?
I mentioned all this to Joanne one evening and she pointed out that you could probably do the entire show for free if you just ordered all the dongles from Amazon and sent them back before the return policy expired. It’s a genius idea.
You probably wouldn’t be able to remove the dongles from those overwrought and horrible plastic moulds that all electronics are packaged in but that might also be more interesting than not.
Piotr Adamczyk was one of the other keynote speakers at NDF this year and he spoke about the work he’s doing with the Google Art Project (GAP). He pointed out that GAP is really more like a Rachel Whiteread scuplture than anything else; that GAP can show you the shape of the inside of a museum. It’s a lovely way to think about what they’re doing whatever else you think about the project.

To likewise belabour injection-moulded packaging would be a mostly silly way to articulate and conceptualize how we might display a circus show of VGA dongles. But only a little. Given how difficult is it to remove anything from moulded packaging (without also destroying the packaging itself) putting the whole thing on a pedastal un-opened might be the only way we have to consider the formal qualities of the shells that house all the electronic barnacles that cover our lives.
So, yeah. Welcome to 2013.












{kind=link}