I made another small thing. Again, another way for me to experiment with the Collection API, and again, another way to experiment with new ways of accessing the collection. This time, there aren’t many screen shots to display–there is no website to look at. This time, it’s “Welcome to object phone!”
(718) 213-4915
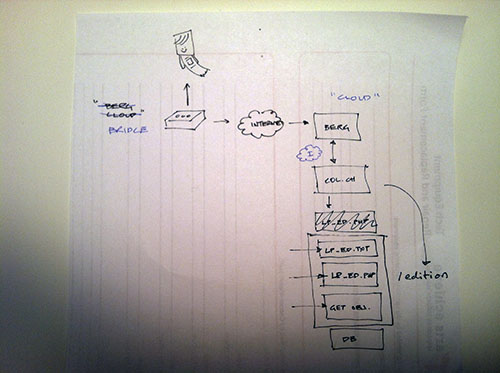
“Object Phone” is ( presently ) a very, very simple implementation of a way to explore our collection by dialing a telephone, or sending a text message. I had been thinking of a few of the more popular museum oriented audio tour products, and how they all seem to be very CMS style in their design, and wondering if we could just use our own API.
For example, TourML and TAP ( which offer the web programmer a very powerful framework for programming a mobile guide using the Drupal CMS ) are very nice, but they are still very dependent on content production. The developer or content manager has to build and curate all of the content for the “tour.” This might be a good way to go about things, especially if you are leaning on an existing Drupal installation for a good deal of your content, but I was looking for a way to access existing data, and specifically the data in our collection website.
In the beginning of developing our collection website, we went through the process of assigning EVERYTHING a unique “bigint” in the form of what we are referring to as an “artisinal integer.” This means that each object record, each person record and each, well, everything else has a unique integer which no other thing can have. This is not in place of accession numbers–we will probably always have accession numbers The nice thing about unique integers is that they’re really easy to deal with on a programmatic level.
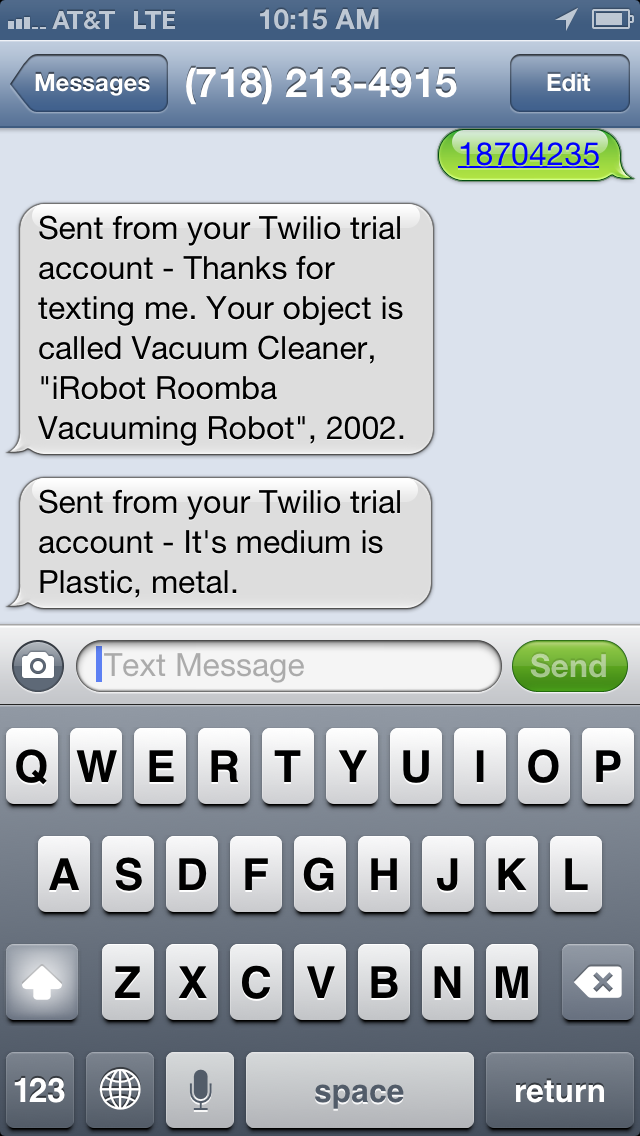
For example, if you text 18704235 to 718-213-4915 you should get a response that looks like the screenshot below. In fact you can text any object id number from our collection and get a similar response.
You can also dial that same number and use your keypad to either search the collection by object ID, or ask for a random object. The application will respond to you using a text to speech converter, which is usually pretty good.
Presently, the app is not replying with a whole lot of information. You essentially get the object’s title and medium field if it has one. In many cases, asking for a random object may just result in something like “Drawing.” Many of our object records don’t have much more useful information than this, and also, I am trying to wrangle with the idea of how much information is useful in a voice and text message ( with a 160 character limit per SMS).
The whole system is leveraging the Twilio service and API. Twilio offers quite a range of possibilities, and I am very excited to experiment with more. For example, instead of text to speech, Twilio can play back .wav files. Additionally, Twilio can do things like dial another phone number, forward calls and record the caller’s voice. There are so many possibilities here that I wont even begin to list them, but for example, I could easily see us using this to capture user feedback in our galleries by phone and text.
I’m very interested in figuring out a way to search by voice. I’m sort of dreaming of programming the thing to go “Why don’t you just tell me the object number!” as in this great episode of Seinfeld which you can watch by clicking the image below.
 If you are interested, I have also made the code public on this Gist. It’s pretty messy and redundant right now, but you’ll get the idea.
If you are interested, I have also made the code public on this Gist. It’s pretty messy and redundant right now, but you’ll get the idea.
One of the more complicated aspects of this project will be designing the phone interface so it makes sense. Currently, once you hear an object play back, the system just hangs up on you. It would be nice to offer the user a better way to manipulate the system which is still pleasant and easy to understand. By that same token, there is a completely different approach that is needed for the SMS end of things as you don’t really have a menu tree, but instead of list of possible commands the user need to learn. Fortunately, there is a ton of great work that has already been accomplished in this arena, specifically by the Walker Art Center’s very long running and very yellow website Art on Call.
Source code at github.com/cooperhewitt/objectphone