
Have you ever noticed the way people in museums always take pictures of object labels? On many levels it is the very definition of an exercise in futility. Despite all the good intentions I’m not sure how many people ever look at those photos again. They’re often blurry or shot on an angle and even when you can make out the information there aren’t a lot of avenues for that data to get back in to the museum when you’re not physically in the building. If anything I bet that data gets slowly and painfully typed in to a search engine and then… who knows what happens.
As of this writing the Cooper-Hewitt’s luxury and burden is that we are closed for renovations. We don’t even have labels for people to take pictures of, right now. As we think through what a museum label should do it’s worth remembering that cameras and in particular cameras on phones and the software for doing optical character recognition (OCR) have reached a kind of maturity where they are both fast and cheap and simple. They have, in effect, showed up at the party so it seems a bit rude not to introduce ourselves.
I mentioned that we’re still working on the design of our new labels. This means I’m not going to show them to you. It also means that it would be difficult to show you any of the work that follows in this blog post without tangible examples. So, the first thing we did was to add a could-play-a-wall-label-on-TV endpoint to each object on the collection website. Which is just fancy-talk for “another web page”.
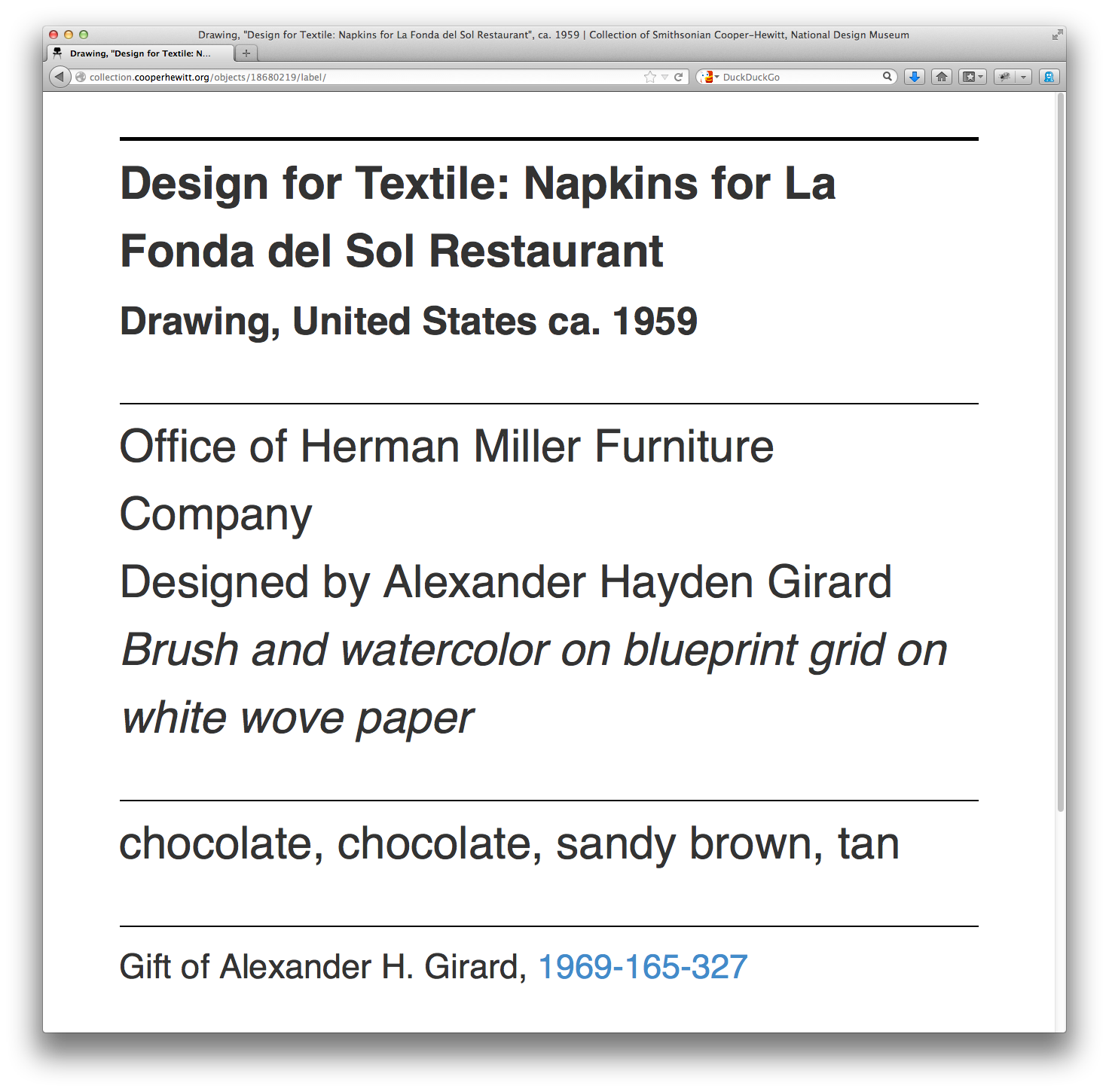
Simply append /label to any object page and we’ll display a rough-and-ready version of what a label might look like and the kind of information it might contain. For example:
https://collection.cooperhewitt.org/objects/18680219/label/
Now that every object on the collection website has a virtual label we can write a simple print stylesheet that allows us to produce a physical prototype which mimics the look and feel and size (once I figure out what’s wrong with my CSS) of a finished label in the real world.

So far, so good. We have a system in place where we can work quickly to change the design of a “label” and test those changes on a large corpus of sample data (the collection) and a way to generate an analog representation since that’s what a wall label is.
Careful readers will note that some of these sample labels contain colour information for the object. These are just placeholders for now. As much as I would like to launch with this information it probably won’t make the cut for the re-opening.
Do you remember when I mentioned OCR software at the beginning of this blog post? OCR software has been around for years and its quality and cost and ease-of-use have run the gamut. One of those OCR application is Tesseract which began life in the labs at Hewlitt-Packard and has since found a home and an open source license at Google.
Tesseract is mostly a big bag of functions and libraries but it comes with a command-line application that you can use to pass it an image whose text you want to extract.
In our example below we also pass an argument called label. That’s the name of the file that Tesseract will write its output to. It will also add a .txt extension to the output file because… computers? These little details are worth suffering because when fed the image above this is what Tesseract produces:
$> tesseract label-napkin.jpg label Tesseract Open Source OCR Engine v3.02.01 with Leptonica $> cat label.txt ______________j________ Design for Textile: Napkins for La Fonda del Sol Restaurant Drawing, United States ca. 1959 ________________________________________ Office of Herman Miller Furniture Company Designed by Alexander Hayden Girard Brush and watercolor on blueprint grid on white wove paper ______________._.._...___.___._______________________ chocolate, chocolate, sandy brown, tan ____________________..___.___________________________ Gift of Alexander H. Girard, 1969-165-327
I think this is exciting. I think this is exciting because Tesseract does a better than good enough job of parsing and extracting text that I can use that output to look for accession numbers. All the other elements in a wall label are sufficiently ambiguous or unstructured (not to mention potentially garbled by Tesseract’s robot eyes) that it’s not worth our time to try and derive any meaning from.
Conveniently, accession numbers are so unlike any other element on a wall label as to be almost instantly recognizable. If we can piggy-back on Tesseract to do the hard work of converting pixels in to words then it’s pretty easy to write custom code to look at that text and extract things that look like accession numbers. And the thing about an accession number is that it’s the identifier for the thing a person is looking at in the museum.
To test all of these ideas we built the simplest, dumbest HTTP pony server to receive photo uploads and return any text that Tesseract can extract. We’ll talk a little more about the server below but basically it has two endpoints: One for receiving photo uploads and another with a simple form that takes advantage of the fact that on lots of new phones the file upload form element on a website will trigger the phone’s camera.
This functionality is still early days but is also a pretty big deal. It means that the barrier to developing an idea or testing a theory and the barrier to participation is nothing more than the web browser on a phone. There are lots of reasons why a native application might be better suited or more interesting to a task but the time and effort required to write bespoke applications introduces so much hoop-jumping as to effectively make simple things impossible.

Given a simple upload form which triggers the camera and a submit button which sends the photo to a server we get back pretty much the same thing we saw when we ran Tesseract from the command line:

We upload a photo and the server returns the raw text that Tesseract extracts. In addition we do a little bit of work to examine the text for things that look like accession numbers. Everything is returned as a blob of data (JSON) which is left up to the webpage itself to display. When you get down to brass tacks this is really all that’s happening:
$> curl -X POST -F "file=@label-napkin.jpg" https://localhost | python -mjson.tool
{
"possible": [
"1969-165-327"
],
"raw": "______________j________nDesign for Textile: Napkins for La Fonda delnSol RestaurantnnDrawing, United States ca. 1959nn________________________________________nOffice of Herman Miller Furniture CompanynnDesigned by Alexander Hayden GirardnnBrush and watercolor on blueprint grid on white wove papernn______________._.._...___.___._______________________nchocolate, chocolate, sandy brown, tannn____________________..___.___________________________nGift of Alexander H. Girard, 1969-165-327"
}
Do you notice the way, in the screenshot above, that in addition to displaying the accession number we are also showing the object’s title? That information is not being extracted by the “label-whisperer” service. Given the amount of noise produced by Tesseract it doesn’t seem worth the effort. Instead we are passing each accession number to the collections website’s OEmbed endpoint and using the response to display the object title.
Here’s a screenshot of the process in a plain old browser window with all the relevant bits, including the background calls across the network where the robots are talking to one another, highlighted.
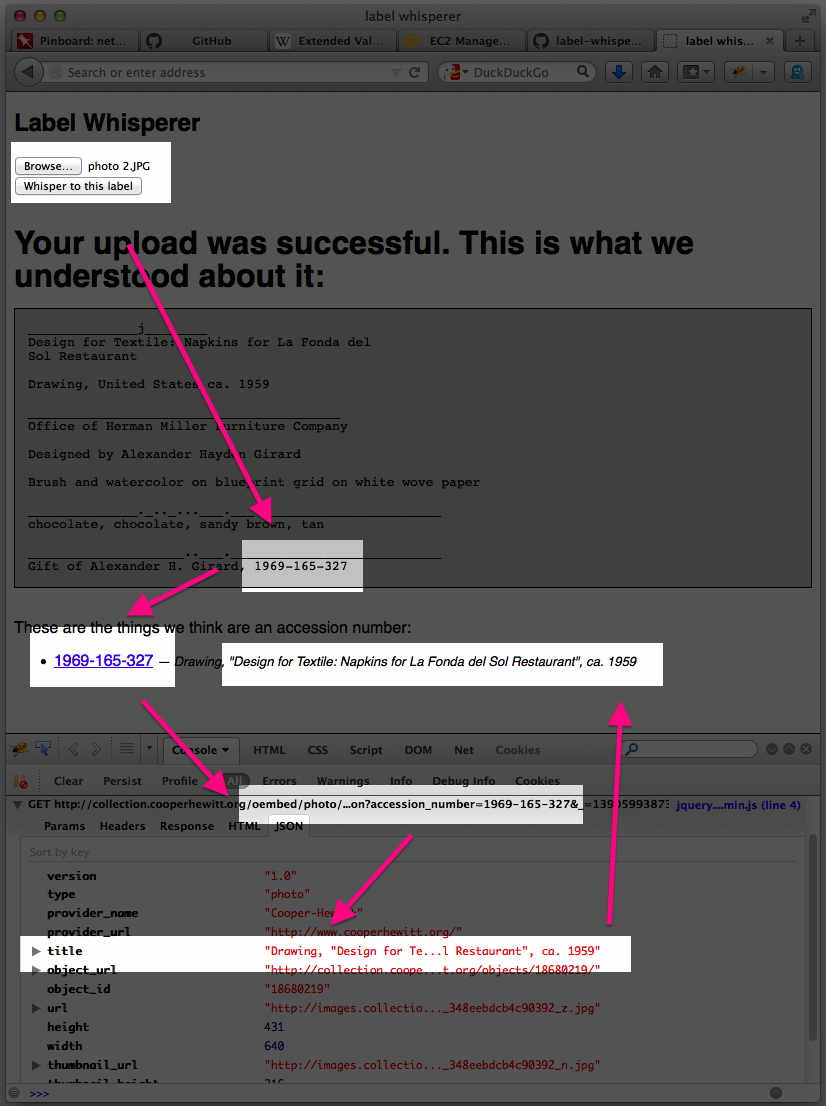
- Upload a photo
- Extract the text in the photo and look for accession numbers
- Display the accession number with a link to the object on the CH collection website
- Use the extracted accession number to call the CH OEmbed endpoint for additional information about the object
- Grab the object title from the (OEmbed) response and update the page
See the way the OEmbed response contains a link to an image for the object? See the way we’re not doing anything with that information? Yeah, that…
But we proved that it can be done and, start to finish, we proved it inside of a day.
It is brutally ugly and there are still many failure states but we can demonstrate that it’s possible to transit from an analog wall label to its digital representation on a person’s phone. Whether they simply bookmark that object or email it to a friend or fall in to the rabbit hole of life-long scholarly learning is left an as exercise to the reader. That is not for us to decide. Rather we have tangible evidence that there are ways for a museum to adapt to a world in which all of our visitors have super-powers — aka their “phones” — and to apply those lessons to the way we design the museum itself.
We have released all the code and documentation required build your own “label whisperer” under a BSD license but please understand that it is only a reference implementation, at best. A variation of the little Flask server we built might eventually be deployed to production but it is unlikely to ever be a public-facing thing as it is currently written.
https://github.com/cooperhewitt/label-whisperer/
We welcome any suggestions for improvements or fixes that you might have. One important thing to note is that while accession numbers are pretty straightforward there are variations and the code as it written today does not account for them. If nothing else we hope that by releasing the source code we can use it as a place to capture and preserve a catalog of patterns because life is too short to spend very much of it training robot eyes to recognize accession numbers.
The whole thing can be built without any external dependencies if you’re using Ubuntu 13.10 and if you’re not concerned with performance can be run off a single “micro” Amazon EC2 instance. The source code contains a handy setup script for installing all the required packages.
Immediate next steps for the project are to make the label-whisperer server hold hands with Micah’s Object Phone since being able to upload a photo as a text message would make all of this accessible to people with older phones and, old phone or new, requires users to press fewer buttons. Ongoing next steps are best described as “learning from and doing everything” talked about in the links below:
- Michal Migurski’s Walking Papers and Walking Papers Cheaply
- Astronomy.net’s Making the Sky Searchable
- The Royal Observatory’s Introducing Astrotags — if you don’t bother following any of the other links at least watch this because it’s basically the best thing ever
- Matt Jones’ Product Sketch: Clocks for Robots
Discuss!