

Claude Shannon
Up until recently our collections website displayed search results ordered by, well, nothing in particular. This wasn’t necessarily by design, we just didn’t have any idea of how we should sort the results. We tossed around the idea of sorting things by date or alphabet, but this seemed kind of arbitrary. And as search results get more complex, ‘keyword frequency’ isn’t necessarily equivalent to ‘relevance’.
We added the ability on our ‘fancy search‘ to sort by all of these things, but we still needed a way to present search results by default.
Enter Claude Shannon and a bit of high level math (or ‘maths’ if, like some of the team, are from this thing called ‘the Commonwealth’).
Claude Shannon was a pretty smart guy and back in 1948 in a paper titled “A Mathematical Theory of Communication” he presented the idea of Entropy, or information theory. The concept is actually rather simple, and relies on a quick analysis of a dataset to discover the probability of different parts of data within the set.
For images you can think about it by looking at a histogram and thinking of the height of each bar in the histogram as a representation of the probability that a particular pixel value will be present. With this in mind you can get a sense of how “complex” an image is. Images with really flat histograms ( lots of pixel values present lots of times ) will have a very high Entropy, where as images with severely spiked histograms ( all black or all white for example ) will have a very low Entropy.
In other words, images with more fine detail have a higher Entropy and are more complicated to express, and usually take up more room on disk when compressed.

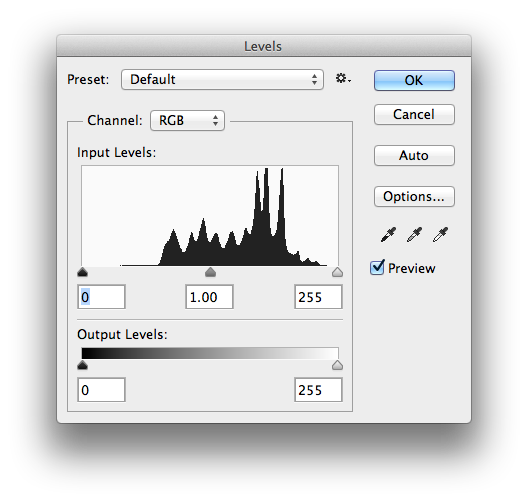
Think of an image of a wallpaper pattern like this one. It has a really high Entropy value because within the image there is lots of fine detail and texture. If we look at the histogram for the image we can see that there are lots of pixel values represented pretty evenly across the graph with a few spikes in the middle most likely representing the overall palette of the image.
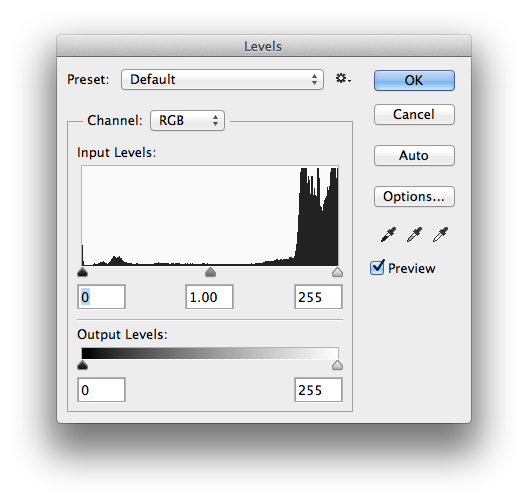
On the other hand, check out this image of a pretty smooth vase on a white background. The histogram for this image is less evenly distributed, leaning towards the right of the graph and thus has a much lower Entropy value.

 We thought it might be interesting to sort all of the images in our collection by Entropy, displaying the more complex and finer detailed images first, so I built a simple python script that takes an image as input and returns its “Shannon Entropy” as a float.
We thought it might be interesting to sort all of the images in our collection by Entropy, displaying the more complex and finer detailed images first, so I built a simple python script that takes an image as input and returns its “Shannon Entropy” as a float.
https://gist.github.com/micahwalter/5237697
To chew through the entire collection we built this into a simple “httpony” and built a background task to run through every image in our collection and add its Shannon Entropy as a value in the collection database. We then indexed these values in Solr and added the option to sort by “image complexity” in our Fancy Search page.
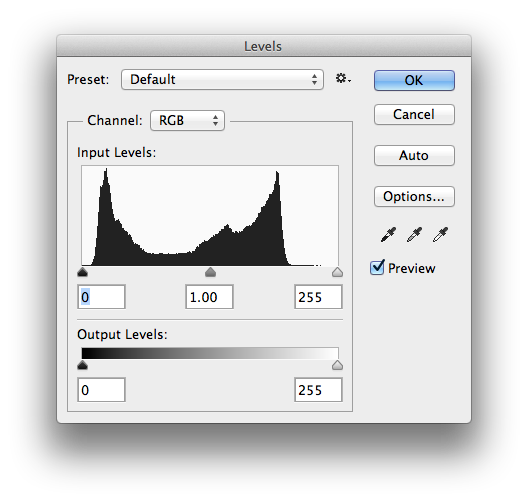
Sorting by Shannon Entropy is kind of interesting, and we noticed right away that a small byproduct of this process is that objects that simply dont have an image wind up at the end of the sort. In the end we liked the search results so much that we made “image complexity” the default sort across the entire website. You can always go into Fancy Search and change the sort criteria to your liking, but we thought image complexity seemed to be a pretty good place to start.
But what is the relationship between Claude Shannon and Shannen Doherty? Well, it looks like Shannen, herself, has a very high Shannon Entropy…

This is very, very interesting. At first, I thought you should sort by images that have a low entropy first (thinking that simple images might be a nice and accessible way to enter the results for the viewer). But when you noted that objects with no images are low entropy and therefore appear at the end, I liked that a lot.
Thanks Jeff,
I’m working on a number of other “image metrics” that you’ll be able to sort with in the future…stay tuned…
Entropy works better than “busyness.” Excellent.
Great writeup, and thanks for the code! Wonder if there’s any benefit to doing this on RGB channels separately, as opposed to summed? (or for that matter, converting to another colorspace, i.e. LAB, and running the analysis on one of those channels?
Peter, Nice idea. I would imagine you could get some interesting results by separating out the color channels and trying different color spaces, depending on what you were looking for. Might be really useful for low contrast/night-vision sorts of images..but we dont have too many of those!
Hmmm. You’ve taken pixels and mapped them to Shannon’s concept of “symbol”. By ignoring the part of Shannon’s paper about Markoff (his spelling) processes, you essentially end up assuming that each pixel’s probability is independent, which it rarely is in any meaningful image. So, your measure of “entropy” will in general not really map monotonically to any compression method that takes advantage of the fact that pixel probabilities usually aren’t independent (JPEG). For example, take an image of a color palette like (http://us.123rf.com/400wm/400/400/sangoiri/sangoiri1202/sangoiri120200004/12185321-color-palette-color-chart-for-prepress-printing-and-calibration-business.jpg). It has a fairly flat histogram, of course, which you would claim means it has high entropy. But a human looking at it sees very low entropy and little complexity, and even a GIF processor can highly compress it. I think characterizing the pixel histogram as “entropy” is fundamentally unhelpful unless you’re dealing with images whose pixels were randomly generated. IMHO.
Pingback: HTTP ponies | Cooper Hewitt Labs