If you’ve taken a look at Cooper Hewitt’s website in the past few months, you may have noticed some subtle changes to our main navigation. Until recently, all visitors to the main museum site saw exactly the same options in the main navigation. Anyone could (and still can) use the nav to retrieve a visit, explore special events and public programs, visit the blog or the shop, and travel to our collection and tickets sites to take care of business over there.
But previously, our main site could not tell whether users were signed into their Cooper Hewitt accounts. And now?


We know who they are, everywhere! From anywhere within the cooperhewitt.org domain, a user can sign into their account or create a new one, and we’ll remember them as they browse. We’re seriously excited about this change.
The Cooper Hewitt account already plays an important role in helping our visitors reconnect with the experiences they’ve had inside the museum. When a visitor returns home from Cooper Hewitt, enters their ticket shortcode, and explores the objects they collected with the Pen, their user account allows them to store this visit so that they can come back to it again and again. Having an account also allows visitors to save collection objects to a digital shoebox, take personal notes on things they’ve seen at the museum, and download or gaze fondly at their creations from the Immersion Room and the interactive tables. For now, that’s about it — and as account experiences go, that’s pretty cool. But lately at Labs, we’ve been thinking about what else we might be able to do for visitors who choose to sign up for a Cooper Hewitt account.
The first step we’ve taken toward an improved Cooper Hewitt account experience is to make creating or accessing an account as seamless and consistent as possible. In reviewing our main navigation this fall, we realized that while our collection and ticketing sites made clear how you could connect to your account, our main site presented some substantial barriers. Finding your way to your account required locating the correct sub-menu item and navigating a circuitous path to our collection site, all before any signing in could commence. This required intent and some perseverance on the part of the visitor — not to mention prior knowledge that a Cooper Hewitt account is a thing one can have. (And sad as this is for us, we know there are at least a handful of you out there who don’t know this. Try it! You’ll like it.)
We wanted to make it much easier for visitors to access their accounts and to use the cool features available only to signed-in users. To do this, we need to know a user’s login status everywhere in our domain. This helps us get users where they really want to go. Is this an existing user who just wants to get to their saved visits quickly? Is this a new user who wants to sign up for an account, so that they can get started exploring the collection online? And thinking further down the line: does this user want to see all the tickets they’ve purchased, or manage their membership status and newsletter subscriptions, or explore data around their interactions with the collection — starting from anywhere in the Cooper Hewitt family of websites?
This unified experience requires Single Sign-On (SSO) authentication across all our sites. SSO is a method of user authentication that allows a collection of sites to share awareness of a user’s data, so that the user doesn’t need to sign in repeatedly as they move from site to site within the network.
This is a perfect method for us, because each of the websites we run is a separate application hosted on a subdomain of cooperhewitt.org. For now, this includes our main website, collection website, ticketing website, and a handful of other microsites. It also includes the dedicated instance that takes care of all SSO logic, which we call You. For security reasons, You is the only one of our servers that communicates directly with our user accounts database. This data is exposed internally through a private REST API, which allows us to verify and update user information from any of our sites with an authorized access token. Regardless of a user’s starting point within the Cooper Hewitt ecosystem, they’ll have to communicate with You to sign up for, sign into, or sign out of their account, before returning from whence they came.
Our collection and ticket sites had been using SSO for a while, but our main website was not. Implementing SSO on our main site would be a challenge, because while most of our sites are custom applications built on Flamework, an open-source PHP framework, our main site is actually a WordPress site dressed in the same clothes.
First, a little background on how the SSO flow currently works within a Flamework PHP app, of which our collection site is a good example. Every page load on the collection site triggers login_check_login(), a PHP function to check the user’s current login status, which:
- Looks for the user ID in a global config variable,
$GLOBALS['cfg']['user']['id'].
- If the user ID is not set, looks to the browser for an authorized cookie, which if found we decrypt using mcrypt. (More in a moment on how that cookie gets there.)
- Decodes the decrypted cookie, which contains a user’s numeric ID and base64-encoded password.
- Queries our
user_accounts database to retrieve user data by ID.
- Compares the decrypted password from the cookie to the password pulled from our database.
If everything checks out, we confirm the user as signed in and set $GLOBALS['cfg']['user']['id'] appropriately. The user will now pass future login checks, so long as the authorized cookie remains in their browser. If any of these tests fail, the global variable remains empty, and the user is considered signed out.
On every page that requires a user to be signed in — your saved visits page, for example — we run login_ensure_loggedin(), which looks for $GLOBALS['cfg']['user']['id'] and redirects signed-out users to the collection sign-in page, along with a redir parameter pointing to the current URI.
When the user lands on the collection sign-in page, we build a request parameter that contains this redir param, alongside encoded server data and information about the SSO-enabled receiver (in this case, the collection site). The user is then kicked over to the sign-in page on You with these params in tow.
Once the user lands on the sign-in page, we validate the request data sent over by the receiver (here, collection) to ensure that the user has come to You from a friendly place. Then we double check that the user is actually signed out by running login_check_login() again , expecting another negative response. Finally, if all of these checks pass, we display the sign-in form to the user.
The user fills out their email and password and submits the form, which we validate both client-side and server-side using the You API. Once a user submits a valid form, we sign them in using login_do_login(), which:
- Generates an authorized cookie, encrypts it using mcrypt, and secures it so that it’s visible only over HTTPS.
- Sets the cookie in the user’s browser, giving it the name stored in
$GLOBALS[‘cfg’][‘auth_cookie_name’].
- Looks at the
redir parameter passed down by the SSO receiver, and sends the user back to their starting point.
Now the user is signed in, cookied, and passing all login checks back on the collections site — and on any of our SSO-enabled sites. Users who need to sign up for an account go through a similar process that also includes writing new information to the user_accounts database. This flow is fairly seamless, in part because Flamework apps understand each other well and can communicate whatever pieces of data are needed to handle users securely.
The real work from here was providing our WordPress (WP) site with the data and logic necessary to establish a similar flow. My task was to write a plugin that would enable our WP site to:
- Check whether or not a user is signed in.
- Allow signed-in users to access their account page directly from the main nav.
- Prompt signed-out users to sign in or sign up, also from the main nav.
- Adapt the items shown in the main nav based on a user’s login status.
Back in 2015, Micah wrote wp-cooperhewitt, a WP plugin for talking with our collections API. This plugin has been live on our site since then, and right now we’re using it to enable a number of fun features on our main site. We decided that I would simply expand this plugin to take care of the SSO business as well. (And yes, next steps for this project should include breaking apart this plugin into a handful of plugins with separate purposes.)
Doing it the Wrong Way
For SSO to work, our main site needs to check a user’s login status on every page load, much like our Flamework apps do. To enable this we need to place our login-checking code within the appropriate part of the WP initialization process. WP provides a series of hooks, somewhat similar to events in JavaScript, which allow plugin developers to insert custom callback functions, or actions, into the page load at chosen points.
My first attempt at SSO implementation registered an sso_check_login() action during page load, just after the theme was set up, using the after_theme_setup hook. This function relied on PHP’s $_COOKIE superglobal variable and a handful of WP admin dashboard settings to locate an authorized cookie and run it through a series of checks nearly identical to those in our Flamework code. Once we’d validated the signed-in user (or not), we set PHP’s $_SESSION (another superglobal) to reflect the user’s login status, and our header and footer templates reacted accordingly.
Rather than trying to establish a direct database connection here, I adapted the cooperhewitt_api_call() function that Micah had already created, so that we could accommodate requests to the You API as part of verifying the user’s identity.
https://gist.github.com/rnackman/e14e407d17fb6a17de9bcffd5eeae0ea
Despite leaning heavily on what I later learned was some bad WordPress practice, this solution seemed to work on our development server. And then it worked on production, too, and this was cause for much celebration and the eating of an actual cookie — until I signed out of WordPress, and everything broke. Once I was signed out of my WP admin account, the code I’d written was suddenly unable to access anything in the $_COOKIE variable, and our main site could no longer tell whether I was signed into my Cooper Hewitt account.
Huh? I could see the elusive cookie in my browser. I had tested my plugin code on our dev server, both signed into and signed out of my WP admin account. What was different about production? Some irritated Googling revealed that WPEngine, our WP hosting service, uses page caching to improve site performance. This is a great thing on many levels, but it also means that for a non-admin user, site pages are often served from the cache. Any PHP code run upon loading those pages won’t be rerun, so $_COOKIE and $_SESSION weren’t being touched.
Doing it a Better Way
The best way to get around the limitations imposed by page caching, WPEngine suggested, was to tap into WP’s built-in Ajax support. On page load, we’d have to grab the appropriate cookie on the front end and post an Ajax request to the PHP server, which would then trigger a custom action to check for an authenticated user.
First, we enqueue the cooperhewitt_sso script as part of the WP initiation process. Then we expose to the script a local variable ajax_object, which contains the action URL and the sought-after cookie name.
https://gist.github.com/rnackman/faebdd69cb9459654ec1b233593aa55e
When run on page ready, the cooperhewitt_sso script passes the browser cookie to the server-side sso_check_login function and awaits a response containing a signed-in user’s username. Based on this response, the main nav bar elements are modified to expose the appropriate options — either Sign In / Sign Up or a personalized greeting that links the user to their account page.
https://gist.github.com/rnackman/b4bd4a98d3566f9376003f5a0f274072
In the server-side PHP code, the sso_check_login function remained similar to its initial pre-Ajax form, but here it retrieves the cookie from a post request rather than from the $_COOKIE superglobal.
https://gist.github.com/rnackman/c7b68e852e70d6a3e90485fc0249b42a
And it works!
Since launching this feature, we have had 189 new users sign up for accounts directly from our main website — 10.6% of total sign-ups during this period.

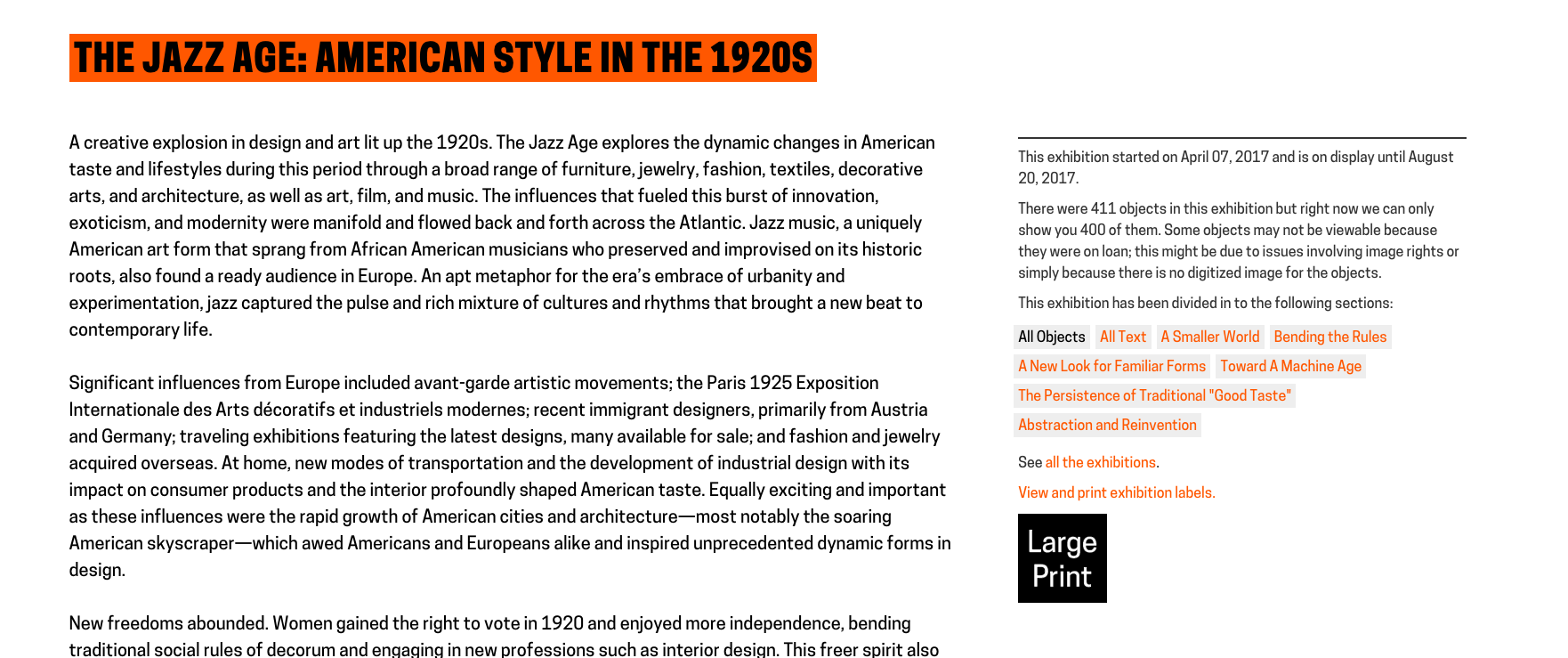
 As of today, when a user visits any exhibition page on our collection site or main website, they’ll see a new option in the sidebar, inviting them to view and print the exhibition labels. The large-print page for each exhibition includes A-panel text alongside all available object images and label chats. If an exhibition is organized into thematic sections, this is reflected in the ordering of the large-print labels, and B-panel text is included alongside the section headers.
As of today, when a user visits any exhibition page on our collection site or main website, they’ll see a new option in the sidebar, inviting them to view and print the exhibition labels. The large-print page for each exhibition includes A-panel text alongside all available object images and label chats. If an exhibition is organized into thematic sections, this is reflected in the ordering of the large-print labels, and B-panel text is included alongside the section headers. To get around this issue, I decided to assemble the large-print label data for certain “oversized” exhibitions in advance and store it in a series of JSON files on the server. A developer can manually run a PHP script to build the JSON files and write them to a
To get around this issue, I decided to assemble the large-print label data for certain “oversized” exhibitions in advance and store it in a series of JSON files on the server. A developer can manually run a PHP script to build the JSON files and write them to a 

