
Today is my last day at Cooper Hewitt, Smithsonian Design Museum. It’s been an incredible seven years. You can read all about my departure over on my personal blog if you are interested. I’ve got some exciting things on the horizon, so would love it if you’d follow me!
Parting gifts
Before I leave, I have been working on a couple last “parting gifts” which I’d like to talk a little about here. The first one is a new feature on our Collections website, which I’ve been working on in the margins with former Labs member, Aaron Straup Cope. He did most of the work, and has written extensively on the topic. I was mainly the facilitator in this story.
Zoomable Object Images
The feature, which I am calling “Zoomable Object Images” is live now and lets you zoom in on any object in our collection with a handy interface. Just go to any object page and add “/zoom” to the URL to try it out. It’s very much an experiment/prototype at this point, so things may not work as expected, and not ALL objects will work, but for the majority that do, I think it’s pretty darn cool!
Here’s an example, zoomed all the way in – https://collection.cooperhewitt.org/objects/18382347/zoom
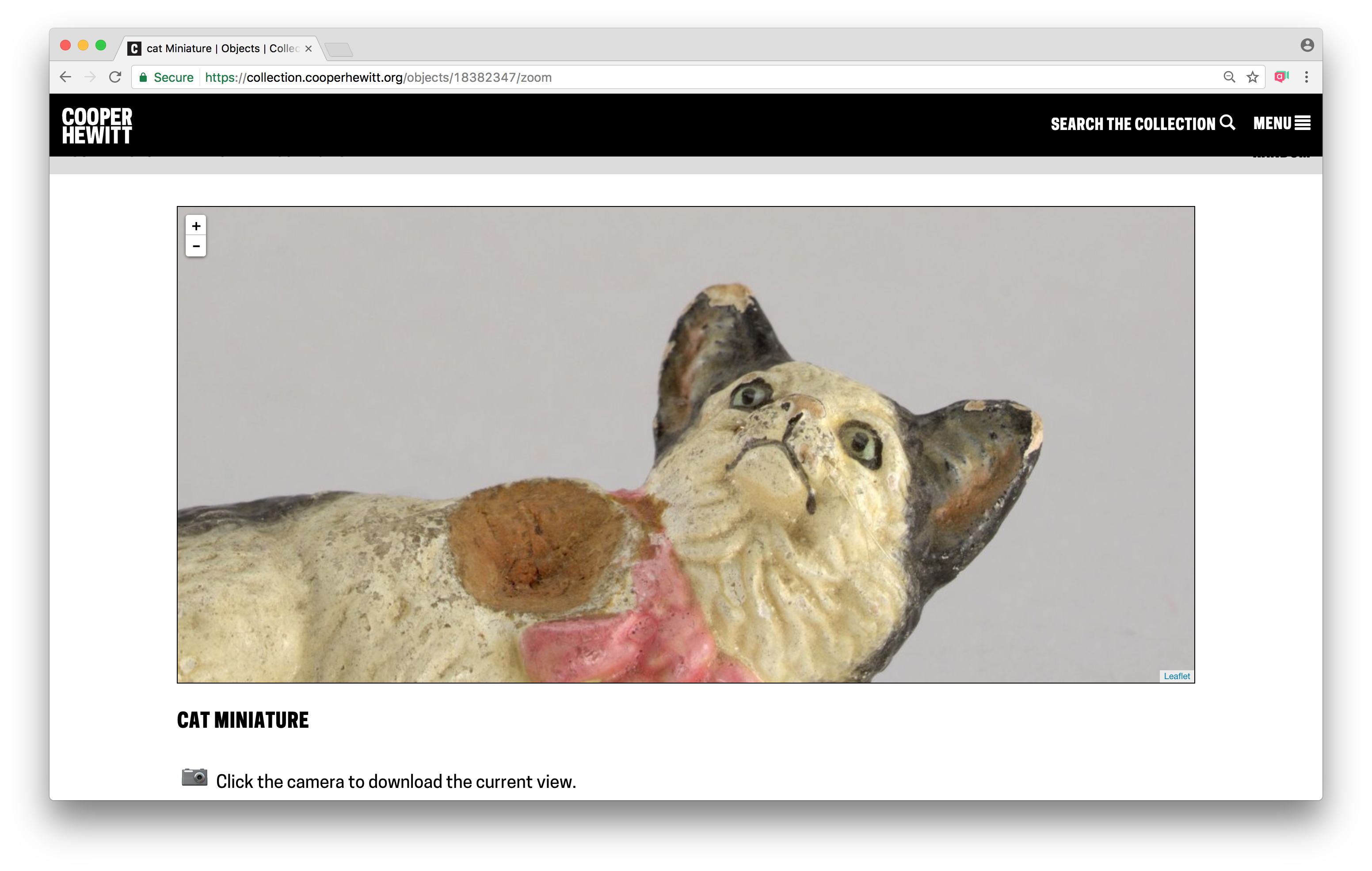
Notice that there is also a handy camera button that lets you grab a snapshot of whatever you have currently showing in the window!
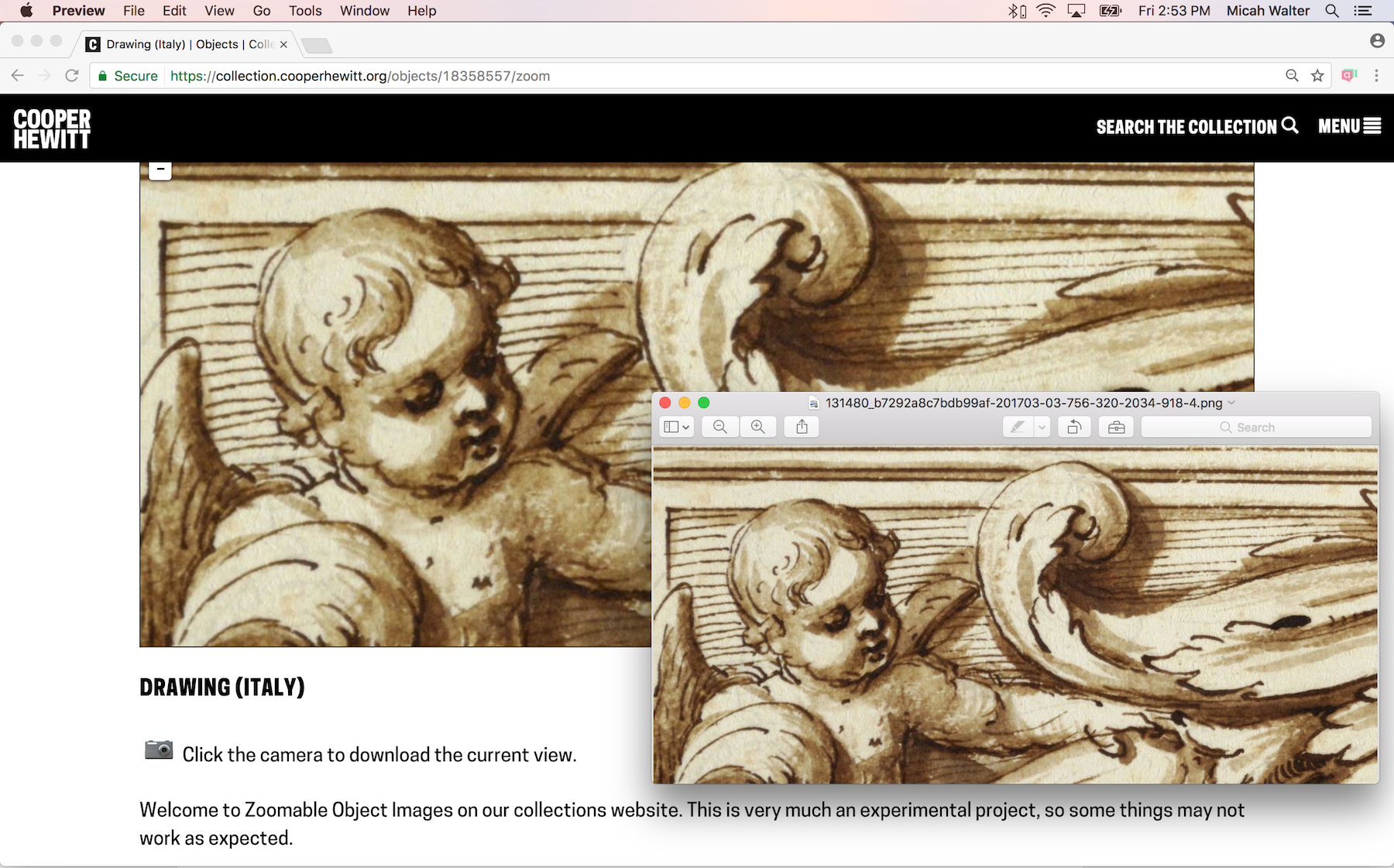
Click on the camera to download a snapshot of the view!

You can’t tell form this image, but you can pinch and zoom this on your mobile device.
Aaron wrote the code to download all of our high res image files and process them into tiles. The code is designed to run with multiple threads so we can get the most efficiency out of our big-giant-ec2 server as possible (otherwise we’d be waiting all year for the results). We found out after a few attempts that there was one major flaw in the whole operation. As we started to generate thousands and thousands of small files, we also started to run up to the limit of inodes available to us on our boot drive. I don’t know if we ever really figure this out, but it seemed to be that the OS was trying to index all those tiny files in some way that was causing the extra overhead. There is likely a very simple way to turn that off, but in the interest of getting the job done we decided to take an alternative route.
Instead of processing and saving the images locally and then transferring them all to our S3 storage bucket, Aaron rewrote the code so that it would upload the files as they were processed. S3 would be their final resting place in any case, so they needed to get there one way or another and this meant that we wouldn’t need so much storage during processing. We let the script run and after a few weeks or so, we had all our tiles, neatly organized and ready to go on S3.
Last but not least, Aaron wrote some code that allowed me to plug it into our collections website, resulting in the /zoom pages that are now available. Woosh!
Check out the code here https://github.com/thisisaaronland/go-iiif – and dive into the tl;dr discussion over here if you’re into this kinda thing.
Cooper Hewitt in a box

The second little gift is around some work I’ve been doing to try and make developing and maintaining code at Cooper Hewitt a tiny bit better.
Since we started all this work we’ve been utilizing a server that sits on the third-floor (right next to Josue) called, affectionately, “Bill.” Bill (pictured above) has been our development machine for many years, and has also served as the server in charge of extracting all of our collection data and images from TMS and getting them published to the web. Bill is a pretty important piece of equipment.
The pros to doing things this way are pretty clear. We always have, at the ready, a clone of our entire technology stack available to use for development. All a developer needs to do is log in to Bill and get coding. Being within the Smithsonian network also means we get built in security, so we don’t need to think about putting passwords in place or trying to hide in plain site.
The cons are many.
For one, you need to be aware of each other. If more than one developer is working on the same file at the same time, bad things can happen. Sam sort of fixed this by creating individual user instances of the major web applications, but that requires a good bit of work each time you set up a new developer. Also, you are pretty much forced to use either Emacs or Vi. We’ve all grown to love Emacs over time, but it’s a pain if you’ve never used it before as it requires a good deal of muscle memory. Finally, you have to be sitting pretty close to Bill. You at least need to be on the internal network to access it easily, so remote work is not really possible.
To deal with all of this and make our development environment a little more developer friendly, I spent some time building a Vagrant machine to essentially clone Bill and make it portable.
Vagrant is a popular system amongst developers since it can easily replicate just about any production environment, and allows you to work locally on your MacBook from your favorite coffee shop. Usually, Vagrant is setup on a project by project basis, but since our tech stack has grown in complexity beyond a single project ( I’ve had to chew on lots of server diagrams over the years ), I chose to build more of a “workspace.”
I got the idea from Dan Phiffer at Mapzen who did the same for their Who’s on First project.
Essentially, there is a simple Vagrantfile that builds the machine to match our production server type, and then there is a setup.sh script that does the work of installing everything. Within each project repository there is also a /vagrant/setup.sh script that installs the correct components, customized a little for ease of use within a Vagrant instance. There is also a folder in each repo called /data with tools that are designed to fetch the most recent data-snapshots from each application so you can have a very recent clone of what’s in production. To make this as seamless as possible, I’ve also added nightly scripts to create “latest” snapshots of each database in a place where they Vagrant tools can easily download them.
This is all starting to sound very nerdy, so I’ll just sum it up by saying that now anyone who winds up working on Cooper Hewitt’s tech stack will have a pretty simple way to get started quickly, will be able to use their favorite code editor, and will be able to do so from just about anywhere. Woosh!
Lastly
Lastly, it’s been an incredible journey working here at Cooper Hewitt and being part of the “Labs.” We’ve done some amazing work and have tried to talk about it here as openly as possible–I hope that continues after I’m gone. Everyone who has been a part of the Labs in one way or another has meant a great deal to me. It’s a really exciting place to be.
There is a ton more work to do here at Cooper Hewitt Labs, and I am really excited to continue to watch this space and see what unfolds. You should too!
Thanks for everything.
-micah
Also published on Medium.