
This part two in a series on digitization. My name is Allison Hale, Digital Imaging Specialist at Cooper Hewitt. I started working at the museum in 2014 during the preparations for a mass digitization project. Before the start of digitization, there were 3,690 collection objects that had high resolution, publication quality photography. The museum has completed phase two of the project and has completed photography of more than 200,000 collection objects.
Prior to DAMS (Digital Asset Management System), image files were stored on optical discs and RAID storage arrays. This was not an ideal situation for our legacy files or for a mass digitization workflow. There was a need to connect image assets to the collections database, The Museum System, and to deliver files to our public-facing technologies.
Vendor Server to DAMS Workflow
The Smithsonian’s DAMS Team and Cooper Hewitt staff worked together to build workflow that could be used daily to ingest hundreds of images. The images moved from a vendor server to Smithsonian’s digital repository. The preparation for the project began with 5 months of planning, testing, and upgrades to network infrastructure to increase efficiency. During mass digitization, 4 Cooper Hewitt staff members shared the responsibility for daily “ingests” or uploads of assets to DAMS. Here is the general workflow:
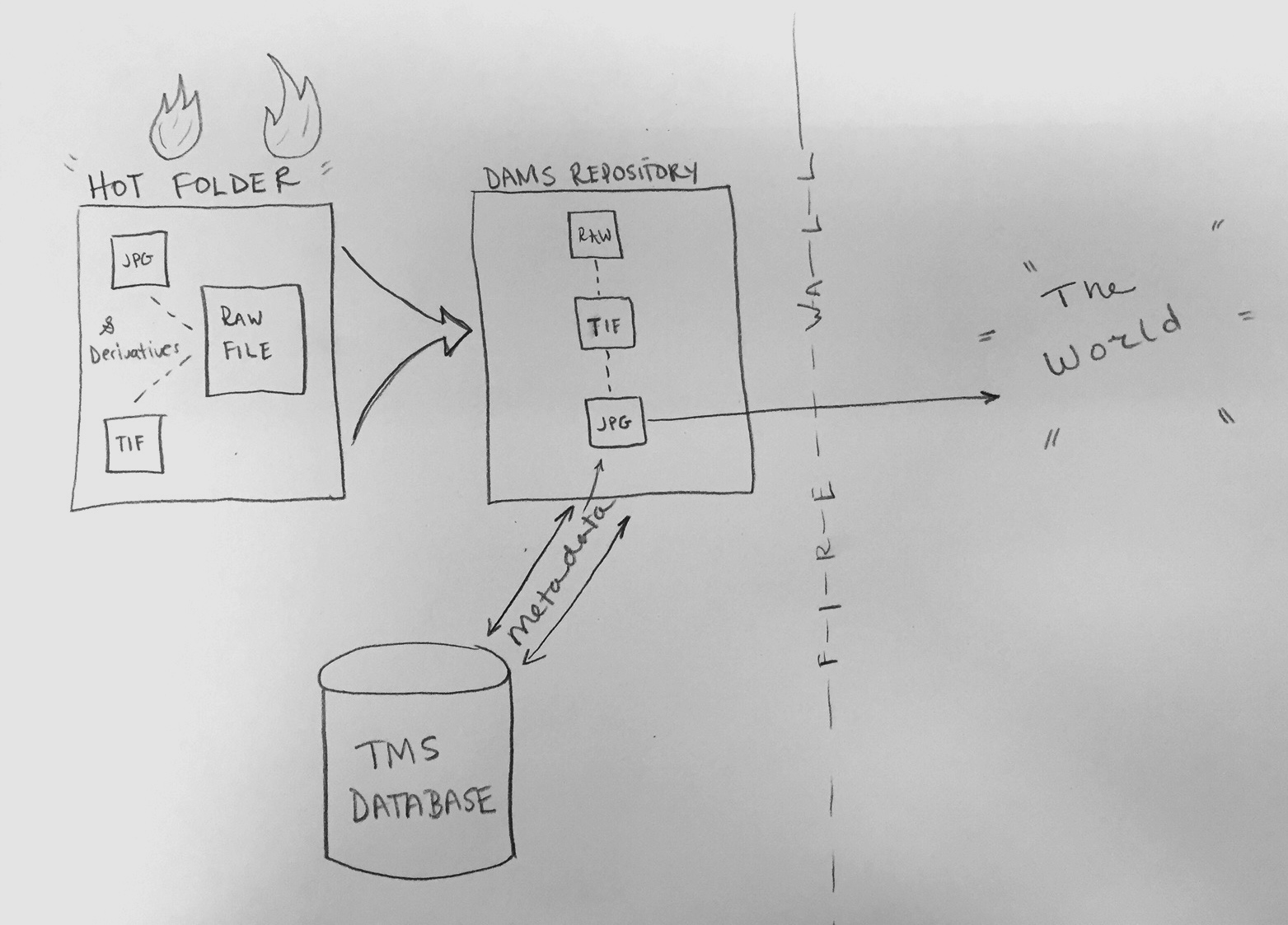
Cooper Hewitt to DAMS workflow.
- Images are stored by vendor in a staging server, bucketed by a folder titled with shoot date and photography station. The vendor delivers 3 versions of each object image in separate folders: RAW (proprietary camera format or DNG file), TIF (full frame/with image quality target), JPG (full-scale, cropped and ready for public audience)
- Images are copied from the server into a “hot folder”–a folder that is networked to DAMS. The folder contains two areas, a temporary area and then separate active folders called MASTER, SUBFILE, SUB_SUBFILE
- Once the files have moved to the transfer area, the RAW files move to the MASTER folder, the TIF to the SUBFILE folder, and the JPG files to the SUB_SUBFILE folder. The purpose of the MASTER/SUB/SUB_SUB structure is to keep the images parent-child linked once they enter DAMS. The parent-child relationship keeps files “related” and indexable
- An empty text file called “ready.txt” is put into the MASTER folder. Every 15 minutes a script runs to search for the ready.txt command
- Images are ingested from the hot folder into the DAMS storage repository
- During the initial setup, the DAMS user created a “template” for the hot folder. The template automatically applies bulk administrative information to the image’s DAMS record, as well as categories and security policies
- Once the images are in DAMS, security policies and categories can be changed to allow the images to be pushed to TMS (The Museum System) via CDIS (Collection Dams Integration System) and IDS (Image Delivery Service)
DAMS to TMS and Beyond: Q&A with Robert Feldman
DAMS is repository storage and is designed to interface with databases. A considerable amount of planning and testing went into connecting mass digitization images to Cooper Hewitt’s TMS database. This is where I introduce Robert Feldman, who works with Smithsonian’s Digital Asset Management Team to manage all aspects of CDIS—Collection Dams Integration System. Robert has expertise in software development and systems analysis. A background in the telecommunications industry and experience with government agencies allows him to work in a matrixed environment while supporting many projects.
AH: Can you describe your role at Smithsonian’s DAMS?
RF: As a member of the DAMS team, I develop and support CDIS (Collection-DAMS Integration System). My role has recently expanded to creating and supporting new systems that assist the Smithsonian OCIO’s goal of integrating the Smithsonian’s IT systems beyond the scope of CDIS. One of these additional tools is VFCU (Volume File Copy Utility). VFCU validates and ingests large batches of media files into DAMS. CDIS and VFCU are coded in Java, and makes use of Oracle and SQL-Server databases.
AH: We understand that CDIS was written to connect images in DAMS to the museum database. Can you tell us more us more about the purpose of the code?
RF: The primary idea behind CDIS is to identify and store the connection between the image in DAMS and the rendition in TMS. Once these connections are stored in the CDIS database, CDIS can use these connections to move data from the DAMS system to TMS, and from TMS to DAMS.
AH: Why is this important?
RF: CDIS provides the automation of many steps that would otherwise be performed manually. CDIS interconnects ‘all the pieces together’. The CDIS application enables Cooper Hewitt to manage its large collection in the Smithsonian IT systems in a streamlined, traceable and repeatable manner, reduces the ‘human error’ element, and more.
AH: How is this done?
RF: For Starters, CDIS creates media rendition records in TMS based on the image in DAMS. This enables Cooper Hewitt to manage these renditions in TMS hours after they are uploaded into DAMS and assigned the appropriate DAMS category.
CDIS creates the media record in TMS by inserting new rows directly into 6 different tables in the TMS database. These tables hold information pertaining to the Media and Rendition records and the linkages to the object record. The Thumbnail image in TMS is generated by saving a copy the reduced resolution image from DAMS into the database field in TMS that holds the thumbnail, and a reference to the full-resolution image is saved in the TMS MediaFiles table.
This reference to the full-resolution image consists of the DAMS UAN (the Unique Asset Name – a unique reference to the particular image in DAMS) appended to the IDS base pathname. By stringing together the IDS base pathname with the UAN, we will have a complete url – pointing to the IDS derivative that is viewable in any browser.
The full references to this DAMS UAN and IDS pathname, along with the object number and other descriptive information populates a feed from TMS. The ‘Collections’ area of the Cooper Hewitt website uses this feed to display the images in its collection. The feed is also used for the digital tables and interactive displays within the museum and more!

A museum visitor looking at an image on the Digital Table. Photo by Matt Flynn.
Another advantage of the integration with CDIS is Cooper Hewitt no longer has to store a physical copy of the image on the TMS media drive. The digital media image is stored securely in DAMS, where it can be accessed and downloaded at any time, and a derivative of the DAMS image can be easily viewed by using the IDS url. This flow reduces duplication of effort, and removes the need for Cooper Hewitt to support the infrastructure to store their images on optical discs and massive storage arrays.
When CDIS creates the media record in TMS, CDIS saves the connection to this newly created rendition. This connection allows CDIS to bring object and image descriptive data from TMS into DAMS metadata fields. If the descriptive information in TMS is altered at any point, these changes are automatically carried to DAMS via a nightly CDIS process. The transfer of metadata from TMS to DAMS is known as the CDIS ‘metadata sync’ process.
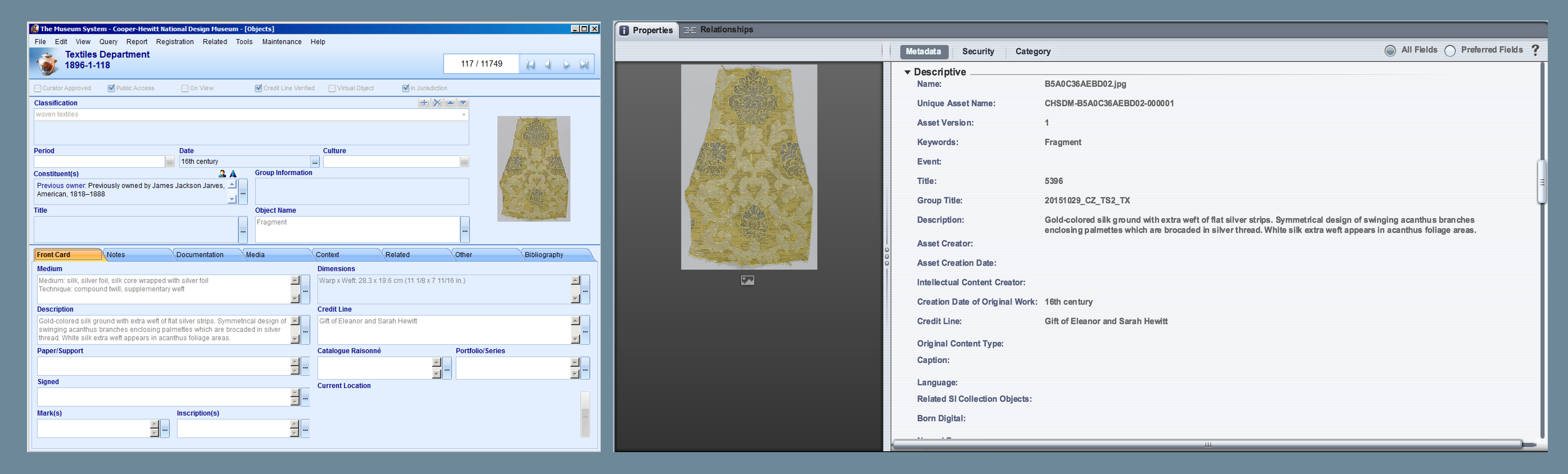
On the left, image of object record in The Museum System database. On right, object in the DAMS interface with mapped metadata from the TMS record. Click photo to enlarge.
Because CDIS carries the object descriptive data into searchable metadata fields in the DAMS, the metadata sync process makes it possible to locate images in the DAMS. When a DAMS user performs a simple search of any of the words that describe the object or image in TMS, all the applicable images will be returned, provided of course that the DAMS user has permissions to see those particular images!
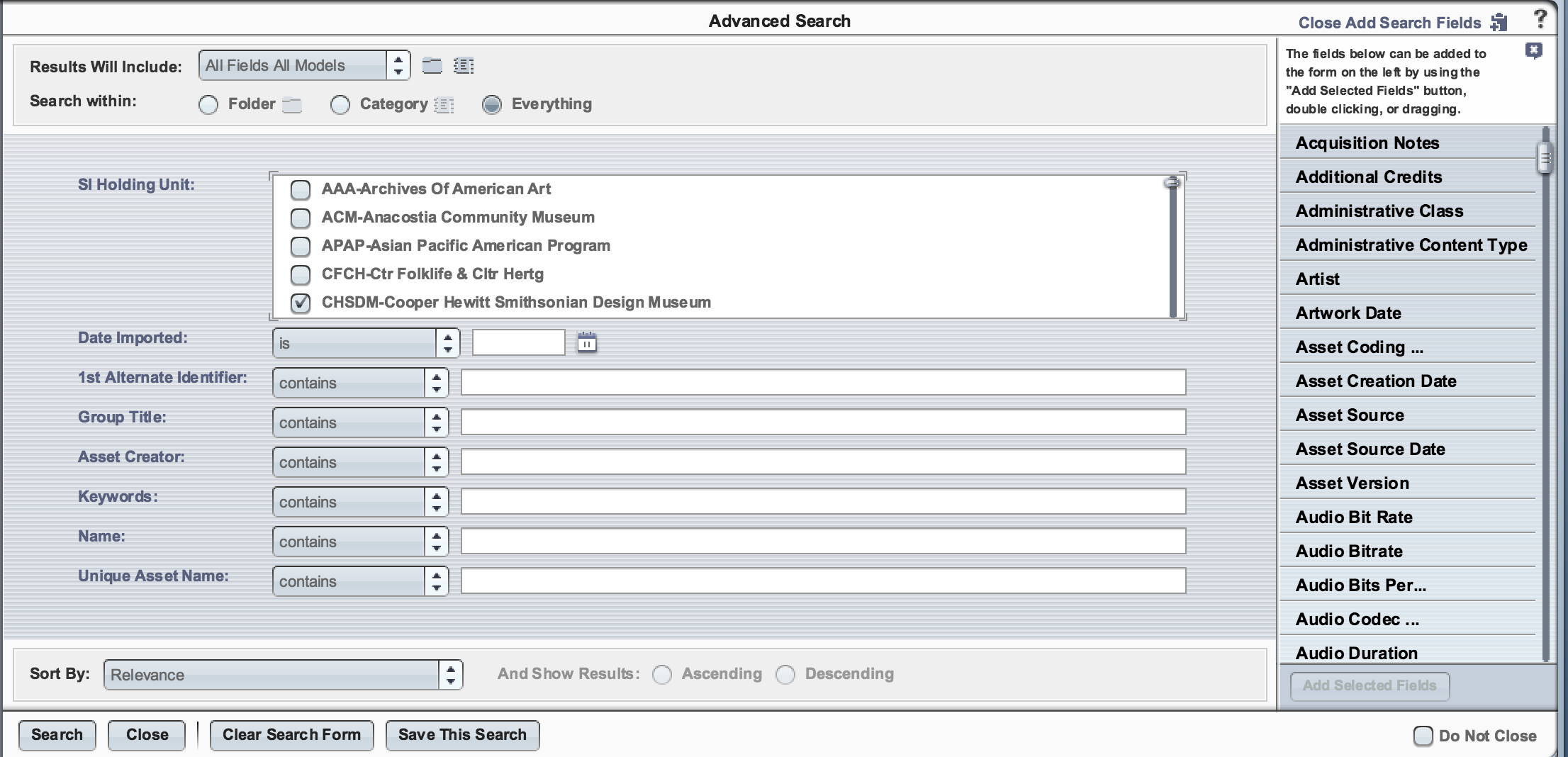
Image of search functionality in DAMS. Click to enlarge image.
The metadata sync is a powerful tool that not only provides the ability to locate Cooper Hewitt owned objects in the DAMS system, but also provides Cooper Hewitt control of how the Smithsonian IDS (Image Delivery Service) displays the image. Cooper Hewitt specifies in TMS a flag to indicate whether to make the image available to the general public or not, and the maximum resolution of the image to display on public facing sites on an image by image basis. With each metadata update, CDIS transfers these settings from TMS to DAMS along with descriptive metadata. DAMS in turn sends this information to IDS. CDIS thus is a key piece that bridges TMS to DAMS to IDS.
AH: Can you show us an example of the code? How was it written?
RF: What was once a small utility, CDIS has since expanded to what may be considered a ‘suite’ of several tools. Each CDIS tool or ‘CDIS operation type’ serves a unique purpose.
For Cooper Hewitt, three operation types are used. The ‘Create Media Record’ tool creates the TMS media, then the ‘Metadata Sync’ tool brings over metadata to DAMS, and finally the ‘Timeframe Report’ is executed. The Timeframe Report emails details of the activity that has been performed (successes and failures) in the past day. Other CDIS operations are used to support the needs of other Smithsonian units.
The following is a screenshot of the listing of the CDIS code, developed in the NetBeans IDE with Java. The classes that drives each ‘operation type’ are the highlighted classes in the top left.
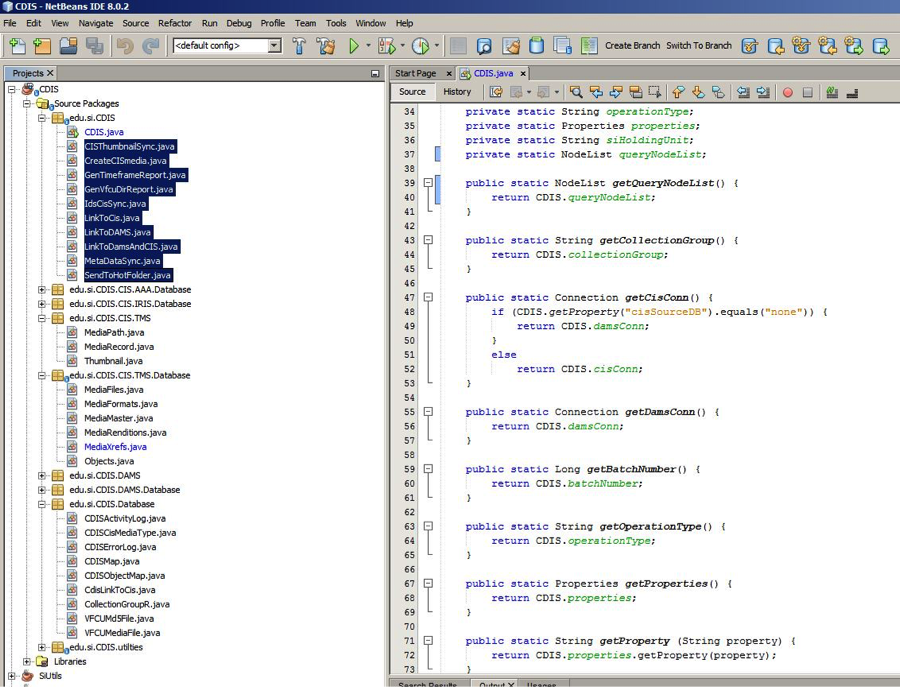
A screenshot of the listing of the CDIS code, developed in the NetBeans IDE with Java.
It may be noted that more than half of the classes reside in folders that end in ‘Database’. These classes map directly to database tables of the corresponding name, and contain functions that act on those individual database tables. Thus MediaFiles.java in edu.si.CDIS.CIS.TMS.Database performs operations on the TMS table ‘MediaFiles’
Something I find a little more interesting than the java code is the configuration files. Each instance of CDIS requires two configuration files that enable OCIO to tailor the behavior of CDIS to each Smithsonian unit’s specific needs. We can examine one of these configuration files- the .xml formatted cdisSql.xml file.
The use of this file is two-fold. First, it contains the criteria CDIS uses to identify which records are to be selected each time a CDIS process is run. The criteria is specified by the actual SQL statement that CDIS will use to find the applicable records. To illustrate the first use, here is an example from the cdisSql.xml file:
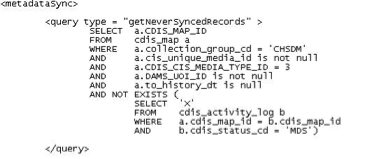
The cdisSql.xml file.
This query is part of the metadataSync operation type as the xml tag indicates. This query obtains a list of records that have been connected in CDIS, are owned by Cooper Hewitt (CHSDM), and have never been metadata synced before (there is no metadata sync record in the cdis_activity_log table).
A second use for the cdisSql.xml file is it contains the mappings used in the metadata sync. Each Smithsonian unit has different fields in TMS that are important to them. Because Cooper Hewitt has its own xml file, CDIS provides specialized metadata mapping for Cooper Hewitt.
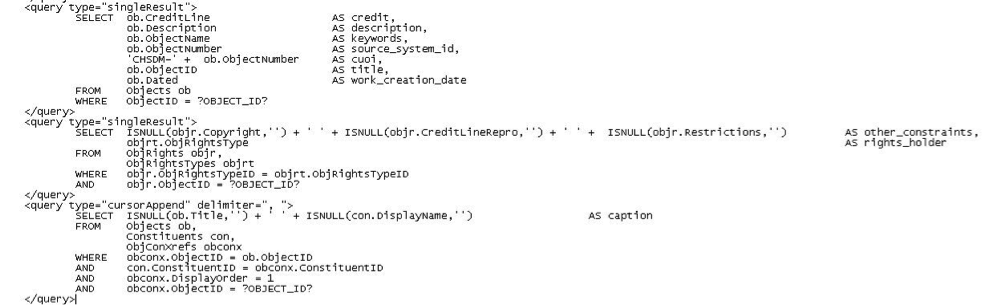
A selection of code for the metadata sync mapping.
If we look at the first query, the creditLine in TMS database table ‘object’ is mapped to the field ‘credit’ in DAMS. Likewise, the data in the TMS object table, column description is carried over to the description field in DAMS, etc. In the second query, there are three different fields in TMS appended to each other (with spaces between them) to make up the ‘other_constraints’ field in DAMS. In the third query (which is indicated to be a ‘cursor append’ query with a delimiter ‘,’ a list of values may be returned from TMS. Each member of the list is concatenated into to a single field in DAMS (the DAMS ‘caption’ field) with a comma (the specified delimiter) separating each value returned in the list from TMS. The metadata sync process combines the results of all three of these queries AND MORE to generate the update for metadata sync in DAMS.
The advantage of locating these queries in the configuration file is it allows for flexibility for each Smithsonian unit to be configured with different criteria for the metadata sync. This design also permits CDIS to perform a metadata sync on other CIS systems (besides TMS) that may use any variety of RDBMS systems. As long as the source data in can be selected with SQL query, it can be brought over to the DAMS.
AH: To date, how many Cooper Hewitt images have been successfully synced with the CDIS code?
RF: For Cooper Hewitt, CDIS currently maintains the TMS to DAMS connections of nearly 213,000 images. This represents more than 172,000 objects.
AH: From my perspective, many of our team projects have involved mapping metadata. Are there any other parts of the code that you find challenging, rewarding?
RF: As for challenges – I deal with many different Smithsonian Units. They each have their own set of media records in various IT systems and they all need to be integrated. There is a certain balancing act that must take place nearly every day. That is provide for the unique needs for each Smithsonian Unit, while also identifying the commonalities among the units. Because CDIS is so flexible, without proper planning and examining the whole picture with the DAMS team, CDIS would be in danger of becoming too unwieldy to support.
As far as rewards- I have always valued projects that allow me to be creative. Investigating the most elegant ways of doing things allows me to keep learning and be creative at the same time. The design of new processes, such as the newly redesigned CDIS and VFCU fulfill that need. But the most rewarding experience is discovering how my efforts are used by researchers, and educate the public in the form of public facing websites and interactive displays. Knowing that I am a part of the historical digitization effort the Smithsonian is undertaking is very rewarding in itself.
AH: Has the CDIS code changed over the years? What types of upgrades have you recently worked on?
RF: CDIS has changed much since we have integrated the first images for Cooper Hewitt. The sheer volume of the data flowing through CDIS has increased exponentially. CDIS now connects well over half a million images owned by nearly a dozen different Smithsonian Units, and that number is growing daily.
CDIS has undergone many changes to support such an increase in scale. In CDIS version 2, CDIS was intrinsically hinged to TMS and relied on database tables in each unit’s own TMS system. For CDIS version 3, we have taken issues such as this into account, and have migrated the backend database for CDIS to a dedicated schema within DAMS database. Cooper Hewitt’s instance of CDIS was updated to version 3 less than two months ago.
Now that the CDIS database is no longer hinged to TMS, CDIS version 3 has opened the doors to mapping DAMS records to a larger variety of CIS systems. We no longer depend the TMS database structure, or even that the CIS system uses the SQL-Server RDBMS. This has enabled the Smithsonian OCIO the ability to expand CDIS’s role beyond TMS and allow integration with other CIS systems such as the National Museum of Natural History’s EMuseum, the Archives of American Art’s proprietary system as well as the Smithsonian Gardens IRIS-BG. All three are currently using the new CDIS today, and there are more coming on board to integrate with CDIS in the near future!
Conclusion
One challenge has been correcting mass digitization images that end up in the wrong object record. If an object was incorrectly barcoded, the image in barcode’s corresponding collections record is also incorrect. Once the object record’s image is known to be incorrect, the asset must be exported, deleted, and purged from DAMS. The image must also be deleted from the media rendition in TMS. When the correct record is located, the file’s barcode or filename can be changed and re-ingested into DAMS. The process can take several days.
The adoption of Smithsonian’s DAMS system has greatly improved redundancy and our workflow with digitization and professional photography. The flexibility of the CDIS coding has allowed me to work with photography assets of our collection’s objects, or “collection surrogates” and images from other departments, such as the Library. Overall, the change has been extremely user-friendly.
Thank you Smithsonian’s DAMS Team!
Also published on Medium.